Przypomnij sobie, jak to było, kiedy ktoś przysłał wam list pocztą. Pewnie napisał wam coś na papierze, włożył go w kopertę, napisał na niej adres i wrzucił do skrzynki. Stamtąd list pewnie powędrował do sortowni, a po sortowaniu wylądował w worku. Następnie worek został załadowany do jakiegoś pojazdu, np. ciężarówki, samolotu albo statku. Pojazd przewiózł list -- przez wodę, powietrze, albo drogą. System pocztowy jest złożony, zaprojektowany żeby umożliwić komunikację między ludźmi, ale jednocześnie by wydajnie grupował wiele listów w jedną przesyłkę. Te same pomysły mają zastosowanie do przesyłania wiadomości przez Internet. Niezależnie od tego czy chodzi o ,,polubienie'' na Facebooku, film, czy email -- protokoły stosowane w Internecie pilnują, żeby wszystko zostało dostarczone do adresata na czas i w całości.
Poniżej przedstawimy pojęcia, algorytmy, techniki, zastosowania i problemy mające związek z protokołami sieciowymi; nie jest to kompletna lista rozwiązań z tej dziedziny, ale powinna wystarczyć do wyrobienia sobie pojęcia czym się zajmuje ten obszar informatyki.
,,Protokół'' to wymyślne słowo oznaczające po prostu ,,uzgodniony sposób robienia czegoś''. Być może słyszeliście to słowo w kiepskim programie o policjantach -- ,,ależ Mietku, to sprzeczne z protokołem!!!'', albo w sensie proceduralnym, np. gdy była mowa o zachowaniu dyplomatów na oficjalnych wizytach. Wszyscy używamy protokołów każdego dnia. Pomyślcie o tym, kiedy będziecie w klasie. Protokół zadawania pytań może wyglądać następująco: podnieś rękę, poczekaj na gest nauczyciela, a następnie zacznij zadawać pytanie.
Proste zadania wymagają prostych protokołów, takich jak ten powyżej; jednak bardziej złożone procesy mogą wymagać bardziej złożonych protokołów. Piloci i załogi samolotów mają (niemal) własny język -- podzbiór normalnego języka, używany do przekazywania informacji takich jak wysokość, kurs, kto jest na pokładzie, status itd.
W Internecie robimy bardzo różne rzeczy (obsługujemy pocztę elektroniczną, Skype'a, przesyłamy wideo, muzykę, gramy, przeglądamy strony, czatujemy), a więc i protokoły do nich używane bardzo się różnią. Tymi protokołami będziemy się zajmować w niniejszym rozdziale -- przedstawimy niektóre z nich, pokażemy jakie problemy rozwiązują i co można zrobić, aby poznać te protokoły z pierwszej ręki. Zacznijmy od omówienia protokołu którego używasz, gdy przeglądasz tę stronę w internecie.
Adres URL strony głównej pierwowzoru tej książki to http://csfieldguide.org.nz. Zapytajcie kilku znajomych, co oznacza ,,http'' -- prawdopodobnie widzieli to tysiące razy... Czy wiedzą, co to jest? W tym rozdziale opowiemy o protokołach wysokiego poziomu, takich jak HTTP i IRC. Czy wiesz, że w tej chwili korzystasz z jednego z nich (protokołu HTTP)?
-
Dla nauczyciela. HTTP na lekcji
Do ćwiczeń z tego rozdziału zalecane są szkolne komputery wyposażone w nowoczesną przeglądarkę z rozszerzeniami deweloperskimi. Chrome można pobrać za darmo i jest to polecana przez nas przeglądarka. Postępuj zgodnie z instrukcjami tutaj, aby uzyskać więcej informacji. Przeglądarka dla programistów nie może wyrządzić żadnej szkody, a może zachęcić do dalszego majsterkowania. Jednak znajomość HTML, JavaScript czy innych aspektów projektowania stron WWW nie będzie pomocna w zabawie z protokołami. Jeśli szkoła nie pozwala na zainstalowanie przeglądarki ze wspomnianymi rozszerzeniami, trzeba po prostu zachęcić uczniów, aby spróbowali w domu. To całkowicie bezpieczne zadanie. Uwaga: Szczegóły dotyczące ładowania stron pojawiają się tylko wtedy, gdy panel konsoli deweloperskiej jest otwarty; konieczne może być odświeżenie bieżącej strony.
Protokół HTTP, czyli HyperText Transfer Protocol jest najpopularniejszym protokołem używanym w Internecie. Zadaniem protokołu jest przesłanie hipertekstu (takiego jak HTML) z serwera na twój komputer. Robi to w tej chwili. Właśnie załadowałeś nasz przewodnik z serwerów, na których został umieszczony. Odśwież stronę, a zobaczysz go w działaniu.
HTTP działa jak prosta rozmowa między klientem a serwerem. Wyobraź sobie, że jesteś w sklepie:
Ty: ,,Czy mogę prosić o napój gazowany?'' Sprzedawca: ,,Jasne, oto puszka napoju.''
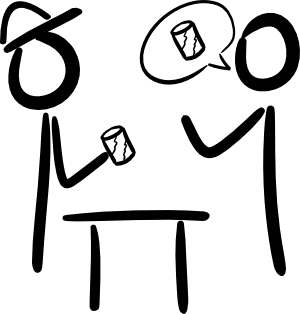
HTTP używa wzorca zapytania -- odpowiedzi w celu zapewnienia niezawodnej komunikacji między klientem a serwerem. ,,Zapytaj o'' to zapytanie, a odpowiedź serwera to po prostu odpowiedź. Zarówno zapytania, jak i odpowiedzi mogą również zawierać inne dane lub zasoby.
-
Co to jest?. Co to jest zasób?
Zasób to dowolne dane na serwerze. Na przykład wpis na blogu, dane klienta, artykuł lub notka prasowa. Firmy lub witryny internetowe tworzą je, czytają, aktualizują i usuwają w ramach normalnej działalności. HTTP dobrze się do tego nadaje. Na przykład, w przypadku strony z wiadomościami, każdego dnia autorzy dodają historie, można je aktualizować lub usuwać, jeśli są przestarzałe, itd. Metody tego rodzaju są potrzebne do zarządzania zawartością na serwerze, a protokół HTTP jest sposobem na zrobienie tego.
Dzieje się to zawsze, gdy przeglądasz sieć; każda przeglądana strona jest dostarczana za pomocą protokołu zwanego po angielsku HyperText Transfer Protocol. Wracając do analogii ze sklepem, rozważmy ten sam przykład, tym razem z większą ilością zasobów pokazanych między gwiazdkami (*).
Ty: ,,Czy mogę prosić o napój gazowany?'' *Podajesz posiadaczowi sklepu 5 PLN.* Sprzedawca: ,,Jasne, oto puszka napoju gazowanego.'' *Podaje paragon i resztę.*

Istnieje dziewięć typów zapytań obsługiwanych przez protokół HTTP, które zostały opisane poniżej.
Żądanie GET zwraca tekst opisujący to, o co prosisz. Np. tak jak powyżej -- jeśli poprosisz o puszkę napoju gazowanego, dostaniesz puszkę napoju gazowanego.
Żądanie HEAD zwraca to, co otrzymasz, gdy wykonasz zapytanie GET. Wygląda to tak:
Ty: ,,Czy mogę prosić o napój gazowany?'' Sprzedawca: ,,Jasne, oto puszka napoju gazowanego, którą otrzymasz.'' *Podnosi puszkę napoju gazowanego.*
Miłą cechą protokołu HTTP jest też to, że umożliwia on również na modyfikację zawartości serwera. Powiedzmy, że jesteś teraz przedstawicielem firmy produkującej napoje gazowane i chcesz zaopatrzyć sklep.
Żądanie POST umożliwia wysłanie informacji w drugą stronę. To zapytanie umożliwia zastąpienie zasobu na serwerze zasobem, który dostarczasz. Używają one tak zwanego Uniform Resource Identifier (jednolitego identyfikatora zasobu) czyli URI. Identyfikator URI to unikatowy kod lub numer zasobu. Za dużo na raz? Wróćmy do sklepu:
Przedstawiciel handlowy: ,,Chciałbym zastąpić tę zniszczoną puszkę napoju gazowanego o kodzie paskowym 123-111-221 tą, która nie jest wgnieciona.'' Sprzedawca: ,,Jasne, została właśnie zastąpiona.''
Żądanie PUT dodaje nowy zasób do serwera, jednak jeśli już istnieje zasób o takim identyfikatorze URI, to zostaje zastąpiony nowym.
Przedstawiciel handlowy: ,,Masz tu jeszcze 10 puszek lemoniady na tę półkę.'' Sprzedawca: ,,Dzięki, włożyłem je na półkę.''
Żądanie DELETE, zgodnie z nazwą, kasuje zasób.
Przedstawiciel handlowy: ,,Nie sprzedajemy już lemoniady z dodatkiem warzyw -- nikt jej nie lubi! Usuń ją!'' Sprzedawca: ,,W porządku, już jej nie ma.''
Istnieją również inne typy zapytań (czyli inne metody HTTP), ale są one rzadziej używane; są to TRACE, OPTIONS, CONNECT i PATCH. Możesz dowiedzieć się więcej na ten temat na własną rękę, jeśli jesteś zainteresowany.
W protokole HTTP pierwszy wiersz odpowiedzi nazywa się wierszem statusu i ma liczbowy kod statusu, na przykład 404, i tekstową przyczynę taką jak np. ,,nie znaleziono''. Najczęściej występuje 200, co oznacza sukces lub ,,OK''. Kody statusu HTTP są podzielone na pięć głównych grup które różnią się pierwszą cyfrą: informacje 1XX, pomyślne 2XX, przekierowania 3XX, błędy klienta 4XX i błędy serwera 5XX. Istnieje wiele kodów statusu odpowiadających konkretnym przypadkom błędu lub powodzenia. W Google jest nawet ciekawy błąd 418: Czajnik: https://www.google.com/teapot.
Co się właściwie dzieje? Przekonajmy się. Otwórz nową kartę w przeglądarce i otwórz stronę główną Przewodnika po informatyce. Jeśli używasz przeglądarki Chrome lub Safari, naciśnij Ctrl + Shift + I w systemie Windows lub Command + Option + I na komputerze Mac, aby otworzyć tzw. inspektora sieci (inaczej konsolę deweloperską). Wybierz kartę Network. Odśwież stronę. Teraz widzisz listę zapytań HTTP, które twoja przeglądarka wysyła do serwera, aby pobrać stronę, którą właśnie przeglądasz. U góry pojawi się zapytanie do ,,index.html''. Kliknij je, a zobaczysz szczegóły nagłówków, podglądu, odpowiedzi, plików cookie i czasu. Te dwa ostatnie na razie zignoruj.
Spójrzmy na kilka pierwszych wierszy nagłówków:
Remote Address: 132.181.2.122:3128
Request URL: http://www.csfieldguide.org.nz/en/index.html
Request Method: GET
Status Code: 200 OK
Remote Address to adres serwera, na którym trzymana jest strona. Request URL jest pierwotnym, żądanym adresem URL. Metoda zapytania powinna być już znana z powyższego tekstu. Jest to zapytanie typu GET, mówiące ,,czy mogę prosić o stronę internetową?'', a odpowiedź to treść strony w języku HTML. Nie wierzysz mi? Kliknij kartę Response. Status Code jest kodem, który strona może zwrócić.
Spójrzmy teraz na nagłówki zapytań (ang. Request Headers). Kliknij view source, aby zobaczyć oryginalne zapytanie.
GET /index.html HTTP/1.1
Host: www.csfieldguide.org.nz
Connection: keep-alive
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml;q=0.9,image/webp,*/*;q=0.8
User-Agent: Chrome/34.0.1847.116
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
Jak widać, komunikat zapytania składa się z następujących elementów:
- Wiersz zapytania w postaci: metoda URI protokół / wersja
- Nagłówki żądania (Accept, User-Agent, Accept-Language itp.)
- Pusty wiersz
- Opcjonalna treść wiadomości.
Spójrzmy na nagłówki odpowiedzi (ang.Response Headers):
HTTP/1.1 200 OK
Date: Sun, 11 May 2014 03:52:56 GMT
Server: Apache/2.2.15 (Red Hat)
Accept-Ranges: bytes
Content-Length: 3947
Connection: Keep-Alive
Content-Type: text/html; charset=UTF-8
Vary: Accept-Encoding, User-Agent
Content-Encoding: gzip
Jak widać, komunikat odpowiedzi składa się z następujących elementów:
- Wiersz statusu, ,,200 OK'' oznacza, że wszystko poszło dobrze.
- Nagłówki odpowiedzi (długość treści, typ zawartości itp.).
- Pusty wiersz.
- Opcjonalna treść wiadomości.
Poćwicz to samo na kilku innych stronach. Na przykład wypróbuj te witryny:
- Stronę bardzo dużą jeśli chodzi o ilość treści, na przykład facebook.com.
- Stronę, która nie istnieje w Google.
- Twoją ulubioną stronę internetową
-
Ciekawostka. Kto wymyślił HTTP?
Powszechnie uznaje się, żę Tim Berners-Lee stworzył HTTP w 1989 roku. Możesz przeczytać o nim więcej tutaj.
-
Dla nauczyciela. IRC na lekcji
W tym podrozdziale sugerujemy skorzystanie z klienta WWW freenode. Umożliwia to na skonfigurowanie własnego kanału, do którego później będą mogli dołączyć uczniowie. Ale jest to usługa publiczna, więc jeśli nazwa Twojego kanału będzie zbyt oczywista, może się zdarzyć, że dołączą do niego przypadkowe osoby. Najlepiej nie używać konwencjonalnych nazw kanałów i użyć ###irc-mojaszkola-aktualnadata czy czegoś podobnego. Uczniowie mogą również pobierać i instalować klienty IRC, ale ich konfiguracja bywa złożona, więc najlepiej na początku korzystać z wersji WWW. Wtedy wystarczy powiedzieć uczniom do którego kanału dołączyć.
Internet Relay Chat (IRC) to system umożliwiający przesyłanie wiadomości w postaci tekstu. W gruncie rzeczy jest to protokół czatu. Używa modelu klient -- serwer. Klienty to programy do czatu zainstalowane na komputerze użytkownika, które łączą się z centralnym serwerem. Klienty przesyłają wiadomości do centralnego serwera, który z kolei przekazuje je do innych klientów. Protokół został pierwotnie zaprojektowany do komunikacji grupowej na forum dyskusyjnym, zwanym kanałem. IRC obsługuje również komunikację w trybie ,,jeden do jednego'' za pośrednictwem prywatnych wiadomości. Może również przesyłać pliki i dane.
Ciekawą cechą IRC jest to, że użytkownicy mogą używać komend do interakcji z serwerem, klientem lub innymi użytkownikami. Na przykład /DIE powie serwerowi, aby się wyłączył (ale zadziała to tylko wtedy, gdy jesteś jego administratorem!), a /ADMIN powie Ci, kto jest administratorem.
Wprawdzie IRC może być dla Ciebie czymś nowym, ale pojęcie rozmowy grupowej online lub pokoju rozmów możesz już znać. Tak naprawdę niczym się od siebie nie różnią. Grupy istnieją w postaci kanałów. Serwer obsługuje wiele kanałów i możesz wybrać, do którego z nich dołączyć.
Kanały zwykle tworzą się wokół określonego tematu, takiego jak Python, muzyka, fani programu TV, gry, czy hakowanie. Konwencja mówi, że nazwy kanałów zaczynają się od jednego lub dwóch symboli #, jak np. #python lub ##TheBigBangTheory. Konwencje różnią się od protokołów tym, że nie są egzekwowane przez protokół, ale ludzie zwykle decydują się postępować zgodnie z nimi.
Aby rozpocząć korzystanie z IRC, najpierw powinieneś zdobyć klienta. Klient to program, który umożliwia ci się połączyć. Zapytaj swojego nauczyciela, którego z nich użyć. W tym rozdziale użyjemy klienta WWW freenode. Sprawdź u swojego nauczyciela, do którego kanału się przyłączyć, ponieważ nauczyciel mógł już założyć kanał specjalnie dla ciebie.
Wypróbuj kilka rzeczy, skoro już tam jesteś. Spójrz na tę listę poleceń (po angielsku) i spróbuj użyć niektórych z nich. Jaką odpowiedź otrzymasz? Czy ma ona sens?
Wypróbuj rozmowę w trybie jeden-na-jeden z przyjacielem. Gdy używa poleceń, widzisz je? Czy działa to w drugą stronę?
Do tej pory rozmawialiśmy o HTTP i IRC. Te protokoły są na poziomie, który zapewnia, że nie musisz się martwić o to, w jaki sposób Twoje dane są transportowane. Teraz omówimy, w jaki sposób Twoje dane są przesyłane niezawodnie i sprawnie, niezależnie od tego co zawierają. Poniżej tego poziomu znajduje się zawodne medium transmisji (takie jak wifi albo kable, które są podatne na zakłócenia), co budzi obawy dotyczące przesyłania danych. Te protokoły prezentują różnie podejścia do problemu skutecznego i / lub wydajnego dostarczania danych.
TCP (Transmission Control Protocol) jest jednym z najważniejszych protokołów w Internecie. Rozbija duże wiadomości na pakiety. Co to jest pakiet? Pakiet to segment danych, który w połączeniu z innymi pakietami tworzy kompletną wiadomość (coś w rodzaju zapytania HTTP, wiadomości email, wiadomości IRC lub pliku takiego jak pobierany obrazek lub utwór muzyczny). W dalszej części tego podrozdziału przyjrzymy się, w jaki sposób pakiety są wykorzystywane do pobrania obrazka ze strony internetowej.
Komputer A wyszukuje plik i dzieli go na pakiety. Następnie przesyła pakiety przez Internet, a komputer B składa je ponownie i przedstawia tobie jako obraz, co zostało pokazane w tym wideo (po angielsku).
Zastanawiasz się pewnie, po co w ogóle dzielimy na pakiety... Czy nie byłoby łatwiej wysłać cały plik? Cóż, to rozwiązuje problem zatorów. Wyobraź sobie, że jesteś z przyjaciółmi w autobusie, w godzinach szczytu i musisz być w domu o piątej. Droga jest zablokowana i nie ma mowy, żebyś wraz z przyjaciółmi dotarł do domu na czas. Decydujecie się wyjść z autobusu i każdy idzie własną drogą. Strony internetowe też tak robią. Są zbyt duże, by podróżować razem, więc są rozdzielane i wysyłane w małych kawałkach, a następnie składane po drugiej stronie.
Dlaczego wszystkie pakiety po prostu nie przechodzą z komputera A do komputera B? Ha! Byłoby świetnie. Niestety nie jest to takie proste. Istnieją pewne problemy, które na rożne sposoby mogą wpływać na pakiety. Te problemy to:
- utrata pakietów,
- opóźnienie pakietu (pakiety przychodzą w złej kolejności),
- uszkodzenie pakietu (pakiet zostaje zmieniony po drodze).
Jeśli więc nie spróbujemy tego naprawić, obraz nie zostanie załadowany, jakieś bity zostaną zgubione lub uszkodzone, a komputer B może nawet nie rozpoznać, co otrzymał!

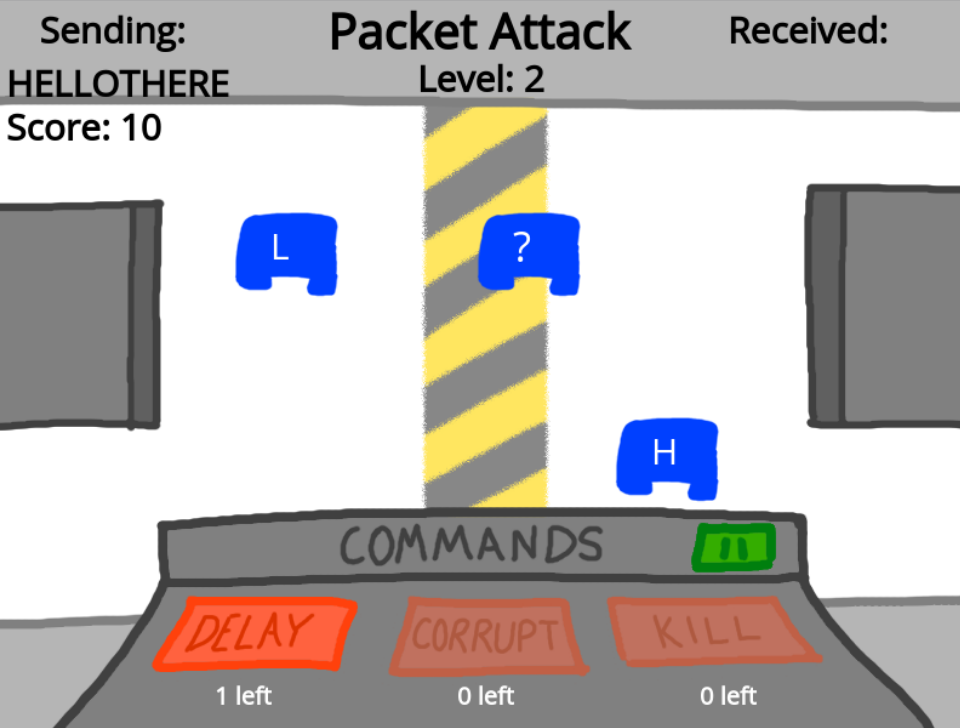
Protokół TCP rozwiązuje te problemy. Aby oswoić się z TCP, zagraj w poniższą grę, zatytułowaną Atak pakietów. W grze Ty grasz rolę problemów (utraty, opóźnienia, zepsucia) i podczas przechodzenia przez kolejne poziomy, zwróć uwagę na sposób, w jaki komputer próbuje je zwalczać. Powodzenia w próbach powstrzymania poprawnego przekazywania wiadomości!
Atak pakietów jest bezpośrednią analogią TCP i został pomyślany jako jego interaktywna symulacja. Stwory pakietowe to segmenty TCP, które podróżują między dwoma komputerami. Strefa żółto-szara jest zawodnym kanałem, podatnym na zakłócenia. Te zakłócenia to użytkownik grający w grę. Pamiętaj, że mamy kluczowe dla tego podrozdziału o mechanizmach na poziomie protokołów transportu problemy -- opóźnienia, uszkodzone i utracone pakiety, a w grze są to ataki: opóźnienie, uszkodzenie, zabicie. Rozwiązania mają postać mechanizmów TCP, które są stopniowo dodawane na kolejnych poziomach. Podobnie jak w TCP, w grze występuje porządkowanie pakietów, sumy kontrolne (tarcze), komunikaty ACK i NACK (powracające stwory) i limity czasu.
-
Dla nauczyciela. Opis gry w atak pakietów
Opis poziomów
- Poziom 1: Bez obrony. Jeden pakiet każdego rodzaju. Wystarczy, że uczniowie pokonają jeden pakiet, za pomocą uszkodzenia lub zabicia, aby kompletna wiadomość nie dotarła do celu.
- Poziom 2: Wiele kopii tego samego pakietu (niosących tę samą informację). 10 pakietów. Uczniowie nie mogą powstrzymać wszystkich pakietów, ale mogą uszkodzić, zabić i opóźnić żeby zdobyć punkty.
- Poziom 3: Pojawiają się tarcze. 10 pakietów. Uczniowie mogą przejść poziom za pomocą zabicia, ale uszkodzenie nie będzie działać.
- Poziom 4: Pojawia się numerowanie. 10 pakietów. Uczniowie mogą przejść poziom za pomocą zabicia, uszkodzenia, ale opóźnienie nie zadziała.
- Poziom 5: Numerowanie i tarcze. 10 pakietów.
- Poziom 6: Numerowanie i potwierdzenia. Podejrzane pakiety będą przez odsyłane i wysyłane ponownie.
- Poziom 7: Numerowanie, tarcze, limity czasu i potwierdzenia. Podejrzane pakiety będą odsyłane i wysłane ponownie. Tego poziomu nie da się przejść.
-
Dla ciekawych. Tworzenie własnych poziomów w grze w atak pakietów
Możesz również tworzyć własne poziomy w grze w atak pakietów. Oto narzędzie do tworzenia poziomów, dzięki któremu możesz eksperymentować z różnymi kombinacjami metod obrony i ataku. Dodanie większej liczby metod obronnych (np. ustawienie tarczy) spowoduje, że trudniej będzie przejść poziom. Zwiększanie liczb przy metodach ataku jest skutkuje zastosowaniem bardziej zawodnego kanału komunikacji.

Porozmawiajmy o tym, co było widać w grze. W jaki sposób na różnych poziomach były rozwiązywane problemy utraty pakietów, opóźnień (zmiany kolejności) i uszkodzenia? TCP ma kilka mechanizmów radzenia sobie z problemami z pakietami.
-
Ciekawostka. Co powoduje opóźnienia, straty i uszkodzenia?
Dlaczego pakiety mają opóźnienia, straty i uszkodzenia? Dzieje się tak dlatego, że gdy pakiety są wysyłane przez sieć, przechodzą przez różne węzły. Te węzły to różne routery lub komputery. Na jednej trasie może być więcej zakłóceń niż na innej (co powoduje utratę pakietów), któraś może być szybsza lub krótsza (co powoduje zmianę kolejności pakietów). Uszkodzenia mogą wystąpić w każdej chwili poprzez zakłócenia elektroniczne.
Po pierwsze, TCP zaczyna się od procedury handshake. Oznacza to w zasadzie, że dwa komputery mówią sobie nawzajem: ,,Hej, będziemy używać TCP do tego obrazka. Rekonstruuj go tak, jak chcesz.''
Dalej mamy uporządkowanie. Ponieważ komputer nie może oglądać danych i układać ich tak, jak możemy my (np. kiedy układamy puzzle albo gramy w Scrabble™), potrzebuje sposobu na ,,zszycie'' pakietów z powrotem. Jak widzieliśmy w grze w atak pakietów, jeśli opóźniłeś wiadomość, która nie miała liczb porządkowych, wiadomość może wyglądać jak ,,HELOLWOLRD''. Tak więc TCP umieszcza numer w każdym pakiecie (zwanym numerem sekwencji), który oznacza jego kolejność. Dzięki temu może je ponownie połączyć. To trochę tak jak wtedy, kiedy drukujesz kilka stron z drukarki i widzisz ,,Strona 2 z 11'' na dole. Jeśli porządek pakietów zostanie zakłócony, TCP zaczeka na wszystkie pakiety, a następnie połączy wiadomość.
Innym rozwiązaniem są sumy kontrolne. Ten pomysł polegający na przechowywaniu dodatkowej informacji na temat danych może ci być znany z rozdziału Kodowanie -- kontrola błędów. Chodzi o to, że dzięki sumie kontrolnej można wykryć błędy, a czasami przy pomocy schematów kodowania można je skorygować. W przypadku pakietu, który można skorygować, jest on poprawiany. Jeśli nie, pakiet jest bezużyteczny i musi zostać wysłany ponownie. W grze tarcze reprezentują sumy kontrolne. Jeśli się uszkodzi sumę kontrolną raz, to może ona usunąć błąd za pomocą korekcji błędów. Jeśli się ją uszkodzi po raz kolejny -- nie będzie w stanie.
A jak to się dzieje, że pakiety są ponownie wysyłane? TCP używa potwierdzania i negatywnego potwierdzenia wiadomości (w skrócie ACK i NACK). Widać je na wyższych poziomach gry, gdy powracają stwory zielone (ACK) i czerwone (NACK). ACKi są wysyłane, aby powiadomić nadawcę, że dotarł pakiet i jest on użyteczny. NACKi są wysyłane, gdy pakiet dociera, ale jest uszkodzony i wymaga ponownego wysłania. ACKi i NACKi są użyteczne, ponieważ tworzą kanał komunikacyjny w przeciwnym kierunku. Jeśli komputer A otrzyma NACK, może ponownie wysłać wiadomość. Jeśli otrzyma ACK, może przestać martwić się potrzebą ponownego wysłania.
Ale czy komputer wyśle pakiet ponownie, jeśli nie usłyszy odpowiedzi? Tak. Nazywa się to limit czasu i jest to ostatnia linia obrony w TCP. Jeśli komputer nie otrzyma potwierdzenia ACK lub NACK, po pewnym czasie po prostu wyśle pakiet ponownie. To trochę tak, jak byś przestał uważać w klasie, a nauczyciel będzie powtarzał Twoje imię, dopóki nie odpowiesz. Może Ci się to zdarzyło... Czasami ACK może się zgubić, więc pakiet zostanie wysłany ponownie po upływie limitu czasu, ale nie przeszkadza, ponieważ TCP rozpoznaje duplikaty i je ignoruje.
To tyle, jeśli chodzi o TCP. Jest to protokół, który przedkłada wierną transmisję danych nad wydajność i szybkość w sieci. Wykorzystuje limity czasu, sumy kontrolne, ACKi i NACKi oraz wielokrotne wysyłanie pakietów, aby niezawodnie dostarczyć wiadomość. A co, jeśli nie potrzebujemy wszystkich pakietów? Czy możemy uzyskać ogólny obraz szybciej? Czytaj dalej...
UDP (User Datagram Protocol) to protokół do wysyłania pakietów, który nie gwarantuje dostarczenia. UDP nie daje gwarancji braku zagubionych pakietów, braku powtarzania pakietów, ani że pakiety zostaną dostarczone we właściwej kolejności. Po prostu przesyła tyle danych, ile mu się uda. Jednak używa sum kontrolnych, więc integralność danych jest zapewniona. To wciąż jest protokół, ponieważ pakiety mają formalną strukturę. Pakiety nadal zawierają adres docelowy i adres źródła, a także rozmiar pakietu.
Czy będziemy używać protokołu, na którym nie można polegać? Tak, ale do niczego ważnego. Pliki, wiadomości, emaile, strony internetowe i inne wiadomości tekstowe używają TCP, ale takie rzeczy jak przesyłanie muzyki, wideo, VOIP itp. używają UDP. Może zdarzyło Ci się połączenie przez Skype, który było kiepskiej jakości? Może wideo migotało, albo dźwięk na ułamek sekundy przerywał? Przyczyną były zagubione pakiety. Ale, rzecz jasna, ogólnie wiedziałeś o co chodzi, a prowadzona rozmowa zakończyła się powodzeniem.
Załóżmy, że chciałbym stworzyć odtwarzacz muzyki online. Dobrze, napiszę więc kod, który będzie odtwarzał utwór, kiedy ktoś naciśnie przycisk PLAY na stronie internetowej. Czy muszę zaprogramować protokół, który przesyła muzykę? W porządku, piszę trochę kodu do UDP. Czy teraz muszę jeszcze zainstalować kable w twoim domu? Nie ma problemu, wskakuję do furgonetki i spędzam kilka tygodni ciągnąc kable do twojego domu, żeby mieć pewność, że pakiety z muzyką będą dostarczone.
Nie. Brzmi to absurdalnie. Jako programista stron WWW nie chcę się martwić niczym innym, tylko tym, żeby mój odtwarzacz był szybki i łatwy w użyciu. Nie chcę się martwić o UDP i nie chcę się martwić o kable. To już jest zrobione -- zakładam, że jest załatwione. I jest.
Protokoły internetowe istnieją w warstwach. Mamy cztery takie warstwy w informatycznym modelu Internetu. Dwie najwyższe warstwy są omówione szczegółowo powyżej, a na dwóch niższych nie będziemy się skupiać. Pierwsza warstwa to warstwa aplikacji, a następnie są warstwy transportowa, internetu i łącza danych.
W każdej warstwie dane składają się ze wszystkich danych z poprzednich warstw, a następnie dodawane są nagłówki i przekazywane dalej. W dolnej warstwie -- warstwie łącza danych -- dodawana jest także stopka. Poniżej znajduje się przykład tego, jak wygląda pakiet UDP, gdy jest przygotowany do transportu.
-
Co to jest?. Nagłówki i stopki
Stopki i nagłówki to w zasadzie metadane pakietu. Informacje o informacji. Podobnie jak nagłówek listu lub przypis, nie są częścią treści, ale znajdują się na stronie. Nagłówki i stopki dokłada się do pakietów żeby przechowywać szczególne dane. Nagłówki są przed danymi a stopki -- po.
Można myśleć o tych protokołach jako o zabawie w przesyłanie paczki. Kiedy wiadomość jest wysyłana przez HTTP, zostaje zapakowana w nagłówek TCP, który następnie jest owijany w nagłówek IPv6, który następnie jest owijany w nagłówek i stopkę sieci Ethernet i wysyłany przez Ethernet. Po drugiej stronie jest ponownie rozpakowany z ramki Ethernet, do pakietu IP, do datagramu TCP, do zapytania HTTP.
-
Co to jest?. Co to jest pakiet?
Nazwa ,,pakiet'' jest ogólnym określeniem jednostki danych. W warstwie aplikacji jednostki danych są nazywane danymi lub zapytaniami, w warstwie transportowej -- datagramami lub segmentami, w warstwie sieci/IP -- pakietami, a w warstwie fizycznej -- ramkami. Każdy poziom ma własną nazwę jednostki danych (segment, pakiet, ramka, zapytanie itd.), ale zamiast tego często używana jest bardziej ogólna nazwa ,,pakiet'', niezależnie od warstwy.
To zgrabny system, ponieważ każda warstwa może założyć, że warstwy powyżej i poniżej dają odpowiednie gwarancje na temat informacji, a każda warstwa (i protokół używany w tej warstwie) ma własną rolę. Jeśli więc tworzysz stronę internetową, możesz po prostu zaprogramować kod strony i nie martwić się o pisanie kodu, żeby strona działała zarówno przez wifi, jak i przez kabel ethernetowy. Podobnym systemem jest system pocztowy... Nie umieszczasz numeru furgonetki kuriera na kopercie! Zajmuje się tym przewoźnik, który potem używa systemu do sortowania poczty i przydzielania jej kierowcom, a potem kierowców do ciężarówek, a potem kierowców do tras... Nie musisz się tym martwić kiedy wysyłasz lub odbierasz list albo korzystasz z usług kuriera.
-
Dla ciekawych. Model OSI a model TCP/IP
Teoretyczny model Internetu OSI różni się od modelu Internetu TCP/IP, którego używają informatycy do projektowania protokołów. OSI jest brane pod uwagę w rozważaniach teoretycznych i opisane w standardach sieciowych, ale ten przewodnik użyje podejścia bardziej praktycznego, ponieważ jest prostsze, a najważniejsze jest przekazanie idei poziomów abstrakcji. Możesz przeczytać więcej o różnicach tutaj.
Jak wygląda segment TCP?
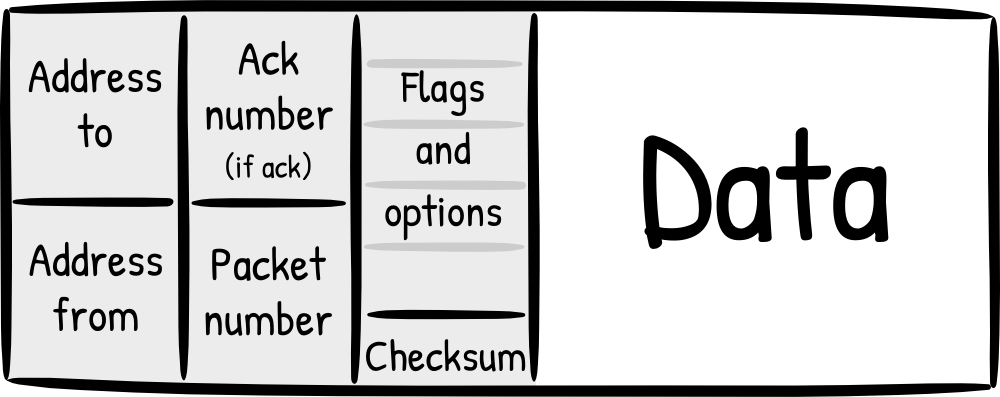
Jak widać, pakiet jest podzielony na cztery główne części: adresy (źródło, cel), numery (numer sekwencji, numer ACK, jeśli jest to potwierdzenie), znaczniki (pilne, suma kontrolna) w nagłówku, a potem rzeczywiste dane. Na każdym poziomie segment staje się danymi dla następnej jednostki danych i ponownie otrzymuje swój własny nagłówek.
Pakiety TCP i UDP mają zapisaną liczbę określającą jakie są duże. Ta liczba oznacza, że pakiet mógłby być prawie dowolnie duży. Czy możesz wymyślić jakieś zalety tworzenia małych pakietów? A dużych? Pomyśl o stosunku danych do informacji dodatkowych (takich jak w nagłówku i stopce).
-
Ciekawostka. Jak wygląda pakiet?
Oto przykład pakietu z sieci autorów... (otrzymany przy użyciu tcpdump na komputerze Mac)
00:55:18.540237 b8:e8:56:02:f8:3e > c4:a8:1d:17:a0:d3, ethertype IPv4 (0x0800), length 100: (tos 0x0, ttl 64, id 41564, offset 0, flags [none], proto UDP (17), length 86) 192.168.1.7.51413 > 37.48.71.67.63412: [udp sum ok] UDP, length 58 0x0000: 4500 0056 a25c 0000 4011 aa18 c0a8 0107 0x0010: 2530 4743 c8d5 f7b4 0042 1c72 6431 3a61 0x0020: 6432 3a69 6432 303a b785 2dc9 2e78 e7fb 0x0030: 68c3 81ab e28b fde3 cfef ae47 6531 3a71 0x0040: 343a 7069 6e67 313a 7434 3a70 6e00 0031 0x0050: 3a79 313a 7165
- Problem dwóch generałów to słynny problem dotyczący protokołów, ilustrujący co się dzieje gdy nie jesteśmy pewni czy wiadomość dotarła.
- Co by było, gdyby wysłać pakiety gołębiami pocztowymi? IP over Avian Carriers
- Protokoły znajdujemy w najdziwniejszych miejscach... Telegraf maszynowy
- Angielskojęzyczny kurs na Coursera: Historia Internetu, technologii i bezpieczeństwa
Jak działa Internet?
Jak działa Internet w 5 minut
- Czemu pakiety się spóźniają? -- ćwiczenie na stronie CS Unplugged (po angielsku, ale posiada polską instrukcję).
- Ślimacza poczta (ang.)
- Code.org -- Internet (ang.)