W początkach ery komputerów komunikacja komputera ze światem zewnętrznym odbywała się poprzez bezpośrednie połączenia kablowe lub poprzez klawiaturę. Współczesne urządzenia cyfrowe wyposażone są w aparaty fotograficzne, kamery, mikrofony i inne urządzenia wejściowe, używane przez oprogramowanie do automatycznego pobierania informacji ze świata, w którym żyjemy. Przetwarzanie obrazów z kamery w celu znalezienia poszukiwanych informacji (wzorców) nazywa się w informatyce rozpoznawaniem obrazów lub widzeniem komputerowym (ang. computer vision).
Wraz ze wzrostem mocy obliczeniowej komputerów, ich miniaturyzacją oraz stopniowym rozwojem algorytmicznych metod przetwarzania danych, komputerowe rozpoznawanie obrazów znajdowało coraz więcej zastosowań. Najpierw w dziedzinach takich jak medycyna, bezpieczeństwo i przemysł, a później coraz częściej w codziennym życiu ludzi.
Oto przykład napisu w języku chińskim.

Jeśli ktoś nie zna pisma chińskiego, to może wspomóc się programem zaintalowanym w smartfonie:
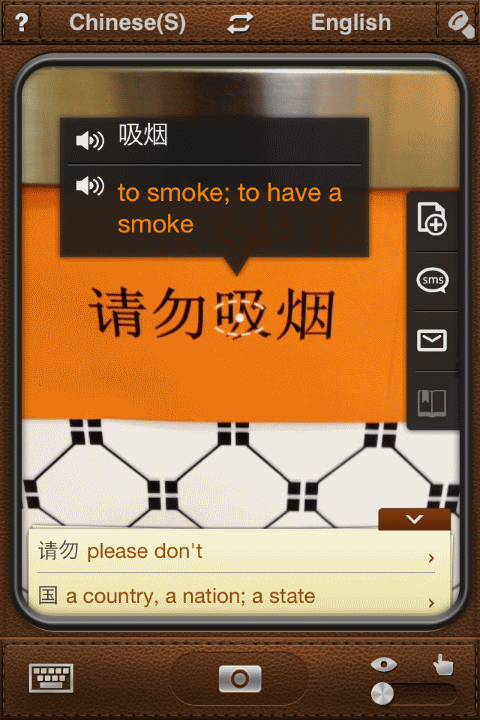
Dla podróżujących takie przenośne małe urządzenie, które ,,patrzy'' i wyświetla tłumaczenie (w naszym przykładzie chodzi o „palić”) jest wielkim udogodnieniem. Zauważyć należy, że tłumaczenie nie obejmuje pierwszej części („prosimy nie”). Trzeba zachować ostrożność!
Rozpoznawanie pisma chińskiego może być czasem niedoskonałe. Oto drogowy znak ostrzegawczy:
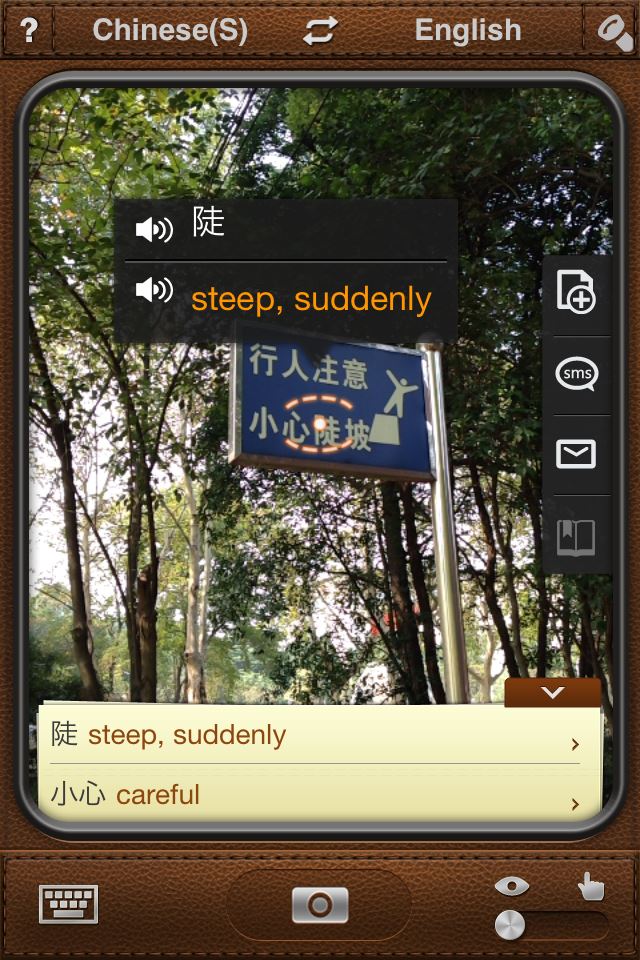
Przedstawiony na zdjęciu smartfon znalazł tłumaczenie dla znaków o znaczeniu ,,stromy'' i ,,ostrożnie'', ale nie rozpoznał ostatniego znaku w linii. Dlaczego?
-
Dla nauczyciela. Znaczenie segmentacji obrazu
Ostatni znak trudniej było rozpoznać, gdyż rysunek postaci człowieka jest zbyt blisko znaku. Oprogramowanie smarfona nie potrafiło określić, gdzie kończy się znak pisma, a gdzie rozpoczyna się rysunek. Ten problem jest znany pod nazwą segmentacji obrazu. Wrócimy do niego później.
Celem tego rodziału jest zaznajomienie czytelnika nie tylko z tematem rozpoznawania obrazów. Proces automatycznego rozpoznawania informacji (przechwytywania danych) ze świata realnego może być użyteczny na różne sposoby. Na przykład znajduje zastosowanie w samochodach, pomagając w unikaniu kolizji na drodze, poprzez ostrzeganie o zbyt małej odległości między samochodami i o innych zagrożeniach. W połączeniu z systemami map (nawigacji) system rozpoznawania obrazów umożliwia budowanie samochodów, które będą się poruszać bez kierowcy. Inny przykład zastosowania to komputerowe systemy ostrzegania wbudowane w wózki inwalidzkie.
Kamery cyfrowe i ludzkie oczy pełnią podobne funkcje: promienie światła przechodzą odpowiednio przez obiektyw kamery lub przez soczewkę oka, tam ulegają załamaniu i w końcu padają na powierzchnię (w oku to siatkówka) pokrytą fotoreceptorami, gdzie są przetwarzane na sygnały elektryczne, które później są przetwarzane przez komputer czy mózg. Oczywiście to tylko uproszczony schemat.
-
Dla nauczyciela. Receptory aparatu cyfrowego
Jest kilka różnych typów sensorów cyfrowego aparatu fotogrficznego. W tym rozdziale ograniczymy się do sensorów CMOS, najbardziej popularnych. Inny typ to Charge-Coupled Device (CCD), znany bardziej wśród fachowców zajmujących się astronomią.
W środku plamki żółtej, czyli części siatkówki ludzkiego oka o największym zagęszczeniu fotoreceptorów, zwanych czopkami, znajduje się zagłębienie zwane dołeczkiem (łac. fovea). To miejsce o największej rozdzielczości widzenia, co oznacza, że odpowiada za postrzeganie szczegółów obiektu, na który patrzymy wprost. Mamy trzy zbiory czopków, wrażliwych na różne barwy (kolory), odpowiednio na światło czerwone, zielone i niebieskie. Inne receptory siatkówki oka to pręciki, które są bardzo wrażliwe na światło, odpowiadające za postrzeganie kształtów i czarno-białe widzenie nawet przy słabym oświetleniu. Obszar siatkówki oka, w którym nerw wzrokowy opuszcza gałkę oczną i biegnie w stronę mózgu to plamka ślepa. Jest on całkowicie pozbawiony fotoreceptorów. Jednak luki w polu widzenia obu oczu nie pokrywają się, więc to, czego nie widzi jedno oko, widzi drugie i powstaje wrażenie, że pole widzenia jest pełne.
Aparaty cyfrowe, inaczej niż oczy, są jednakowej czułości na światło dla całego pola widzenia. Intensywność światła i kolor są rejestrowane przez elementy receptorów RGB wdrukowane w krzemowym układzie scalonym. Te receptory nie mają jednak takiej zdolności jak oczy, jeśli chodzi o zakres poziomów światła podczas przechwytywania informacji. Zwykle, współczesne aparaty cyfrowe potrafią automatycznie dopasować ustawienia w zależności od jasności otoczenia, ale ma to swoją cenę: bardziej szczegółowe informacje o obiektach będą stracone (np. jasne objekty będą na zdjęciu widoczne jako białe plamy).
Jest ważne, by zrozumieć, że ani ludzkie oko, ani cyfrowy aparat fotograficzny -- nawet bardzo drogi -- nie są w stanie zapisać wszystkich informacji o obiektach znajdujących się w polu widzenia. Prowadzone są badania, wspólnie przez inżynierów elektroników i informatyków, których celem jest stworzenie urządzeń jeszcze dokładniej rejestrujacych informacje oraz ich szybkie przetwarzanie.
-
Dla ciekawych. Do dalszej lektury
Więcej na ten temat (w języku angielskim) można przeczytać tutaj: Cambridge in Colour, Pixiq.
Użytkownicy aparatów cyfrowych muszą mieć świadomość istnienia problemu, jakim jest szum. Mówi się o nim wówczas, gdy pojedyncze piksele rejestrowane są jako jaśniejsze lub ciemniejsze niż być powinny. Zjawisko jest skutkiem interfrencji (nakładania się) fal elektromagnetycznych w układach elektronicznych aparatu. Jest to większy problem, gdy poziomy światła są niskie, a aparat próbuje zwiększyć czas ekspozycji obrazu (naświetlania), aby można było zobaczyć więcej. Używa się wtedy ustawień ASA/ISO celem przechwycenia takiej ilości promieni światła, ile to tylko możliwe. Receptory są wówczas bardzo wrażliwe na światło, co wiąże się z ryzykiem interferencji i obraz ma efekt „ziarnistości”.
Efekt szumu jest widoczny głównie jako przypadkowe zmiany pikseli. W przykładzie poniżej widzimy szum typu „sól i pieprz”.

Rozpoznawanie obiektów na obrazach, które zawierają szum jest trudniejsze. Dlatego ważne jest, by szukać coraz lepszych metod redukowania szumu na obrazie. Przy projektowaniu takich metod należy zachować ostrożność. Efektem ubocznym usunięcia szumu nie może być bowiem utrata istotnych informacji o obrazie. Trzeba podkreślić, że stosowane metody są zawsze metodami przybliżonymi rozwiązania problemu, co oznacza, że decyzja o zachowaniu wartości liczbowej lub zmianie wartości dla konkretnego piksela jest efektem domysłu, uzasadnionego domniemania.
-
Dla nauczyciela. Szumy w fotografii
Warto zapoznać się z artykułem o szumach w Wikipedii po angielsku: Image noise.
Ponieważ aparat fotograficzny zapisuje informacje o składowych (czerwonej, zielonej i niebieskiej) osobno dla każdego piksela, to czasami dla zaoszczędzenia na czasie przetwarzania obrazu, jest uzasadnione zapisanie obrazu w odcieniach szarości. Wtedy pomija się informacje o barwie, a zapisuje się tylko informacje o intensywności światła dla każdego piksela.
Dzieki temu można zmieniejszyć poziom szumu na obrazie. Dlaczego? I w jakim stoponiu to pomaga? Aby się przekonać, można zrobić eksperyment: wykonać zdjęcie w miejscu słabo oświetlonym -- można wtedy dostrzec jakby małe łatki na obrazie. Następnie w programie graficznym można zapisać je jako czarno-białe -- czy to zmniejszy efekt szumu?
-
Dla nauczyciela. Zaszumione kanały
Każdy światłoczuły element fotoreceptora aparatu fotograficznego jest równie podatny na szum. To oznacza, że efekty szumu dla różnych składowych RGB są zjawiskami niezależnymi. Jeśli wartości RGB uśredni się (co oznacza jedną liczbę zamiast trzech), to wartość szumu zredukuje się do ok. 1/3. Dlaczego nie dokładnie 1/3? Dlatego, że jesli efekt szumu dotyczy dwóch czy nawet trzech składowych tego samego piksela, to wtedy wartość szumu dla piksela zredukuje się co najwyżej do 2/3.
Zamiast analizować oddzielnie każdą ze składowych RGB piksela, techniki redukujące szum najczęściej działają tak, że sprawdzają piksele sąsiadujące z danym pikselem i na podstawie zebranych informacji przypisują mu przypuszczalną wartość.
W filtrze uśredniającym korzysta się z założenia, że piksele sąsiadujące z danym pikselem są podobne. Wartości przypisane pikselom tworzącym kwadrat, w którego centrum znajduje się dany piksel, są uśredniane i ta wartość średnia jest przypisana pikselowi. Im kwadrat jest większych rozmiarów, tym większe niebezpieczeństwo pojawienia się w wyniku filtrowania efektu rozmycia obrazu, zwłaszcza w przypadku, gdy fragment obrazu przedstawia np. krawędzie obietków (wtedy jasne i ciemne piksele sąsiadują).
W filtrze medianowym stosuje się inne podejście. Odczytuje się wartości sąsiednich pikseli, podobnie jak dla filtru uśredniającego. Następnie szuka się mediany (wartości środkowej) ciągu uporządkowanego odczytanych wartości. Taki filtr daje dobre rezultaty w przypadku, gdy fragment obrazu przedstawia krawędź jakiegoś obiektu, gdyż wówczas wartość mediany będzie jedną z dwóch: albo odpowiadającą jasnemu pikselowi albo ciemnemu pikselowi. Filtr działa też dobrze, gdy analizowany obszar jest w dużej części jednolity, gdyż wówczas obecność mniej licznych pikseli o innej wartości nie ma żadnego wpływu na wartość median. Wadą tej metody jest czas działania, tj. koszt operacji porządkowania wartości przed wyznaczeniem mediany.
Inną techniką jest metoda zwana rozmyciem Gaussa. Działa podobnie do metody uśredniania, ale zamiast wartości średniej korzysta się własności rozkładu normalnego: przyjmuje się, że piksele sąsiadujące bezpośrednio z analizowanym pikselem mają przypisaną wartość najbardziej zbliżoną do poszukiwanej, a piksele położone dalej wręcz przeciwnie.
Uruchom aplikację, używając tego odnośnika i przeprowadź badania według opisu poniżej. Niezbędna będzie kamera internetowa.
Bazą matematyczną przetwarzania obrazu jest w tym przypadku specjalny rodzaj macierzy zwany jądrem splotu (ang. convolution kernel). Każdy z pikseli tworzących obraz jest przetwarzany: wartość mu przypisana jest uśredniania na podstawie wartości sąsiednich pikseli. Zbiór pikseli uśrednionych wartości tworzy nowy obraz. W tym przypadku średnia jest średnią ważoną, tzn. wpływ na średnią wartości pikseli sąsiadujących bezpośrednio z analizowanym pikselem jest większy niż wartości pikseli bardziej oddalonych. Im większe ma być rozmycie, tym większa macierz jest używana, co oznacza większą liczbę obliczeń do wykonania podczas przetwarzania.
Ćwiczenie polega na zbadaniu wpływu różnych ustawień dla filtrów usuwania szumu i określeniu:
- jak radzą sobie z różnymi rodzajami i poziomami szumu,
- jak dużo czasu trwa przetwarzanie (narzędzie wyświetla informację o liczbie ramek przewarzanych w ciągu sekundy),
- jaki mają wpływ na jakość obrazu.
Zdolność komputerów do rozpoznawania twarzy na zdjęciu znajduje wiele zastosowań. Na przykład na portalach społecznościowych coraz częściej pojawiają się narzędzia określania osób na zdjęciu bazujące na algorytmach rozpoznawania twarzy (i dopasowaniu ich do tych zapisanych już w bazie danych).

Jest wiele innych zastosowań. Systemy bezpieczeństwa, np. używane przez służby celne podczas przekraczania granicy między krajami, porównują twarz podróżującego z zdjęciem twarzy na paszporcie czy innym dowodzie tożsamości. Celem przetwarzania obrazu i rozpoznawania twarzy może być dbałość o anonimowość (zachowanie prawa do prywatności) osób, które zostały zarejestrowane przez kamery systemów map ulicznych (np. Google Maps). Wówczas odpowiednie fragmenty zdjęć poddaje się rozmyciu. Współczesne aparaty cyfrowe automatycznie rozpoznają twarze i względem nich dobierają ostrość i oświetlenie kadru przez wykonaniem zdjęcia na podstawie lokalizacji twarzy wewnątrz kadru.
Więcej informacji na ten temat można znaleźć (w języku angielskim) tutaj: Jak działa rozpoznawanie twarzy?, o rozpoznawaniu twarzy na stronie i-Programmer.
Artykuły edukacyjne dotyczące tego zagadnienia znajdują się również na stronie CS4FN
-
Dla nauczyciela. Zadania projektowe
Poniższe zadanie może być ciekawą propozycją na projekt szkolny. Dotyczy zagadnień:
- rozpoznwanie twarzy na zdjęciu cyfrowym,
- zastosowania praktyczne: bezpieczeństwo, znakowanie treści albumów zdjęć,
- algorytm: detektor Haara,
- kryteria oceny: dokładność rozpoznawania twarzy, fałszywe alarmy, szybkość działania,
- autorskie przykłady: zastosowanie metody do własnych zdjęć.
Zacznijmy od ręcznych prób zastosowania kilku metod dla rozpoznania czy dwa zdjęcia ukazują tę samą osobę.
- Zgromadź co najmniej trzy zdjęcia przedstawijące trzy osoby.
- Zmierz cechy twarzy takie, jak odległość między oczami, szerokość ust, wysokość głowy itp. Porównaj wyniki uzyskane na różnych zdjęciach, wyznaczając odpowiednie ilorazy (proporcje).
- Sprawdź, czy na każdym ze zdjęć odpowiednie ilorazy dla konkretnej osoby są takie same. Czy te wartości różnią się w istotny sposób dla różnych osób? Czy te informacje pozwolą na bezbłędne rozpoznanie danej osoby na dwóch zdjęciach?
- Jakie inne cechy osób można by zmierzyć, aby zwiększyć skuteczność rozpoznawania twarzy na zdjęciu?
Sprawdź, jak skuteczne w rozpoznawaniu twarzy są systemy oznaczania (ang. tagging) wbudowane w portale społecznościowe (np. Facebook). Jak radzą sobie z rozpoznawaniem wielu twarzy na jednym zdjęciu? Jak radzą sobie z rozpoznawaniem zdjęć tej samej osoby?
Możesz np. zmienić nieznacznie wygląd twarzy w programie graficznym i sprawdzić skuteczność rozpoznawania osoby po takiej modyfikacji. Możesz posłużyć się dwoma zdjęciami tej samej osoby wykonanymi w odstępie kilku czy kilkunastu lat. Jaka jest skuteczność w rozpoznawaniu twarzy? Dlaczego?
Wypróbuj internetowy program do rozpoznawania twarzy, używający obraz z kamery (np. wbudowanej w laptop). Sprawdź, jak dobrze działa śledzenie ruchu twarzy w tym systemie. Kiedy system zaczyna źle działać? Wystarczy zasłonić jedno oko? Wystarczy założyć kapelusz? Jaką część twarzy trzeba zakryć, aby rozpoznawanie twarzy przestało dobrze działać? Co zrobić, aby system opacznie nie rozpoznał twarzy w miejscu, gdzie jej nie ma?
Użyteczną techniką rozpoznawania obrazów przez komputer jest wykrywanie krawędzi, co oznacza automatyczną lokalizację granicznych części obiektów. To w praktyce oznacza możliwość podziału obrazu na rozłączne obiekty i obszary (segmentyzację).
Oto przykład. Na zdjęciu łatwo dostrzec różne obiekty.

Oto efekt przetwarzania obrazu przez algorytm wykrywania krawędzi:

Można zauważyć, że algorytm przetwarzał również fragment obrazu ukazujący stół; lepiej, aby właściwy proces wykrywania krawędzi poprzedzić innym wstępnym filtrowaniem!
Warto poeksperymentować z wykrywaczem krawędzi na stronie wykorzystującej detektor Canny'ego (więcej informacji o detektorze Canny'ego). Algorytm został zaprojektowany w 1986 roku przez Johna F. Canny'ego.
-
Dla nauczyciela. Zadanie projektowe
Poniższe zadanie może być ciekawą propozycją na projekt szkolny. Dotyczy zagadnień:
- wykrywanie krawędzi na zdjęciu cyfrowym,
- zastosowania praktyczne: segmentacja obrazu (podział obrazu na części),
- algorytm: detektor krawędzi Canny'ego,
- kryteria oceny: dokładność rozpoznawania krawędzi, fałszywe alarmy, szybkość działania,
- autorskie przykłady: zastosowanie metody do własnych zdjęć.
Korzystając z systemu wykrywania krawędzi ze wskazanej wyżej strony internetowej, sprawdź efekt działania detektora dla różnych obiektów czy obrazów, jakie umieścisz w polu widzenia kamery. Zachowaj wybrane obrazy (zrzuty ekranu), jako przykład eksperymentowania z detektorem.
- Czy system wykrył wszystkie krawędzie? Dlaczego niektórych nie wykrył? Czy niektórze krawędzie zostały błędnie zlokalizowane? Dlaczego? Jak sądzisz?
- Czy na efektywność działania wykrywacza ma wpływ oświetlenie pomieszczenia?
- Czy system umożliwia wykrycie granicy między obszarami o dwóch różnych kolorach? Czy kolory muszą się bardzo różnić, aby system działał poprawnie?
- Czy działanie systemu zależy od rodzaju obiektu umieszczonego przed kamerą?
- Jak system radzi sobie z wykrywaniem krawędzi na kartce tekstu?
Dziedzina grafiki komputerowej określana jako rozpoznawanie obrazów szybko się rozwija.
Zwiększają się możliwości teczniczne aparatów cyfrowych: rozdzielczość, czułość (światłoczułość), mniej szumu, działanie w podczerwieni (użyteczne dla wykrywania odległości między obiektami), a jednocześnie spadają ceny. W konsekwencji powszechne staje się np. używanie wielu kamer jednocześnie, umieszczonych pod różnymi kątami aby otrzymać widzenie stereoskopowe.
Trzeba podkreślić, że fundamentalne koncepcje tej dziedziny wymyślone zostały już jakiś czas temu; na przykład pierwszy algorytm segmentacji (podziału na części) był zaproponowany w roku 1967, a pierwszy cyfrowy aparat fotograficzny zbudowano w 1975 roku (o rozmiarach obrazu 100 x 100 pikseli).
(W przyszłość rozdział zostanie uzupełniony.)
Poniższe materiały są po angielsku.
- Wikipedia -- rozpoznawanie obrazów;
- Wikipedia -- MRI.