Błędy w oprogramowaniu zdarzały się zawsze. Czasami jest to mały błąd, który sprawia, że program jest trudny w użyciu; innym razem błąd może spowodować awarię całego komputera. Niektóre błędy w oprogramowaniu są bardziej spektakularne niż inne.
W 1996 roku rakieta ARIANE 5 Europejskiej Agencji Kosmicznej została wysłana w swój pierwszy lot testowy: Odliczanie, zapłon, płomień i dym, wzbijająca się rakieta... następnie BANG! Mnóstwo małych kawałków rozsianych po południowoamerykańskim lesie deszczowym. Badacze musieli połączyć fragmenty rakiety, aby wyśledzić drobny błąd, który spowodował katastrofę. Fragment oprogramowania na pokładzie rakiety, który nie był nawet potrzebny, zgłosił błąd i rozpoczął sekwencję samozniszczenia. Na szczęście nikogo nie było na pokładzie, ale awaria spowodowała straty o wartości 370 mln USD.

W skrajnych przypadkach błędy oprogramowania mogą stanowić zagrożenie dla życia. Taki przypadek miał miejsce w latach osiemdziesiątych, gdy urządzenie do radioterapii spowodowało śmierć 3 pacjentów, dając 100-krotność zamierzonej dawki promieniowania. W 1979 roku komputer armii amerykańskiej prawie rozpoczął wojnę nuklearną, błędnie interpretując testowy scenariusz ataku nuklearnego jako atak Związku Radzieckiego! (Jeśli jesteś zainteresowany innymi błędami oprogramowania, CS4FN wymienia najbardziej spektakularne!)
Dzisiejsze społeczeństwo jest tak uzależnione od oprogramowania, że nie możemy sobie nawet wyobrazić życia bez niego. Pod wieloma względami programy ułatwiły nam życie: piszemy emaile, rozmawiamy z przyjaciółmi na Facebooku, gramy w gry komputerowe i szukamy informacji w Google. Oprogramowanie stało się niewidoczne, często nie wiemy, że z niego korzystamy. Mamy z nim do czynienia w samochodach, sygnalizacji świetlnej, telewizorach, pralkach, toaletach i aparatach słuchowych. Przyzwyczailiśmy się oprogramowania, oczekujemy, że będzie działało przez cały czas!
Dlaczego czasem nie działa? Dlaczego właściwie otrzymujemy komunikaty o błędach? Jak się okazuje, pisanie oprogramowania jest niesamowicie trudne. Oprogramowanie nie jest produktem fizycznym, więc nie możemy po prostu na nie spojrzeć, aby sprawdzić, czy jest poprawne. Dodatkowo, większość oprogramowania, z którego korzystamy na co dzień, jest niezwykle złożona. Windows Vista podobno ma około 50 milionów wierszy kodu; MacOS X ma 86 milionów. Jeśli wydrukujemy systemu Vista, otrzymamy stos kartek wysokości 88 m, czyli stos tak wysoki jak 22 piętrowy budynek lub Statua Wolności w Nowym Jorku! Jeśli chciałbyś przeczytać kod źródłowy systemu Vista i spróbować zrozumieć jak działa (przy prędkości 120 wierszy na godzinę), to musiałbyś poświęcić na to 417 000 godzin lub około 47 lat! (I to tylko aby przeczytać, nie wspominając o napisaniu czegoś podobnego.)

Inżynieria oprogramowania zajmuje się tym, w jaki sposób tworzyć oprogramowanie pomimo ogromnych rozmiarów i złożoności tak, aby ostatecznie otrzymać działający produkt. Po raz pierwszy wprowadzono to zagadnienie do informatyki w latach sześćdziesiątych, w czasie tak zwanego „kryzysu oprogramowania”. Wtedy to zdano sobie sprawę z faktu, że zdolność do tworzenia oprogramowania nie nadąża za rosnącymi możliwościami sprzętu.
Jak sugeruje nazwa inżynieria oprogramowania, będziemy wykorzystywać pojęcia i procesy z innych dziedzin inżynierii (takich jak budowanie mostów lub sprzętu komputerowego) i stosować je do oprogramowania. Uporządkowanie procesu tworzenia oprogramowania okazuje się niezwykle ważne, ponieważ pozwala nam zarządzać rozmiarem i złożonością oprogramowania. Wraz z postępem metod inżynierii oprogramowania, mamy do czynienia z rosnąca liczbą udanych, dużych i złożonych systemów informatycznych, które nie tylko działają dobrze, ale zawierają niewiele błędów. Weźmy za przykład firmę Google, która ma ogromne projekty (wyszukiwarka Google, Gmail, ...) i tysiące programistów pracujących nad nimi, a do tego wciąż tworzy nowe oprogramowanie, które robi to, co powinno.
Od lat sześćdziesiątych inżynieria oprogramowania stała się bardzo ważną częścią informatyki, do tego stopnia, że dzisiejsi programiści częściej są nazywani w języku angielskim inżynierami oprogramowania (ang. software enginneers), niż programistami. Wynika to faktu, że tworzenie oprogramowania to coś więcej niż tylko programowanie. Istnieje ogromna liczba miejsc pracy dla inżynierów oprogramowania, a popyt na wykwalifikowanych pracowników stale rośnie. Wielką zaletą bycia inżynierem oprogramowania jest to, że możesz pracować w dużych zespołach i tworzyć produkty, które będą miały wpływ na życie milionów ludzi! Chociaż można by pomyśleć, że inżynierowie oprogramowania muszą być bardzo inteligentni i nieco -- jak to się mówi w informatycznym slangu -- geekowi, umiejętności komunikacji i pracy zespołowej są w rzeczywistości ważniejsze; inżynierowie oprogramowania muszą pracować w zespołach i komunikować się ze swoimi kolegami z zespołu. Umiejętność pracy z ludźmi jest co najmniej tak samo ważna jak umiejętność pracy z komputerem.
Rosną rozmiary kodów programów, rosną zespoły nad nimi pracujące, a dobre umiejętności komunikacyjne stają się jeszcze ważniejsze niż kiedykolwiek. Co więcej, systemy komputerowe są przydatne tylko wtedy, gdy ułatwiają nam życie, dlatego programiści muszą dobrze rozumieć użytkowników. Z biegiem czasu, gdy komputery stają się mniejsze i tańsze, odeszliśmy od współdzielenia komputerów, do których trzeba czekać w kolejce. Obecnie często posiadamy wiele urządzeń cyfrowych, i to urządzenia muszą czekać na człowieka. W systemie cyfrowym człowiek jest najważniejszym elementem!
-
Ciekawostka. Prawo Moore'a
W 1965 roku Gordon Moore zauważył, że liczba tranzystorów na układach scalonych podwaja się mniej więcej co dwa lata. Oznacza to, że moc obliczeniowa komputerów również podwajała się co dwa lata (czasami podawane jest 18 miesięcy, gdyż przeważnie wzrostowi liczby tranzystorów towarzyszy zwiększenie ich wydajności). Moore powiedział, że spodziewa się kontynuacji tego trendu przez co najmniej 10 lat.
Co ciekawe, prawo Moore'a sprawdzało nie tylko 10 lat, ale nadal działa (chociaż przewiduje się spowolnienie w ciągu najbliższych kilku lat). Oznacza to, że dzisiejsze komputery są ponad 100 milionów razy szybsze niż w 1965 roku! (W 2015 roku minęło 50 lat od 1965 roku, co oznacza, że według prawa Moore'a moc obliczeniowa podwoiła się około 25 razy, \(2^{25}\) wynosi 33 554 432, więc jeśli komputery mogły uruchomić kilkanaście tysięcy instrukcji na sekundę w 1965 roku, to teraz mogą ich wykonać miliardy, i to na znacznie większych danych. Oznacza to również, że jeśli kupisz dziś komputer, możesz żałować za dwa lata, gdy nowe komputery będą dwa razy szybsze. Prawo Moore'a odnosi się także do innych ulepszeń w urządzeniach cyfrowych, takich jak moc przetwarzania w telefonach komórkowych i liczba pikseli w matrycach aparatów cyfrowych.
Dokładne liczby powyżej będą zależeć od tego, co opisują, ale najważniejsze jest to, że moc obliczeniowa wzrasta wykładniczo -- wykładniczy wzrost nie tylko oznacza, że coś dzieje się o wiele szybciej, ale że dzieje się to niewiarygodnie szybko; nic w historii ludzkości nie rozwinęło się tak szybko! Aby zilustrować to w drugą stronę, czas otwarcia aplikacji na smartfonie może wynosić dziś pół sekundy, a na smartfonie z 1965 roku zajęłoby to ponad rok (a telefon prawdopodobnie byłby wielkości boiska do piłki nożnej). Nic dziwnego, że smartfony nie były popularne w latach sześćdziesiątych.
Mimo że inżynieria oprogramowania przeszła długą drogę w ostatnich dziesięcioleciach, pisanie oprogramowania jest nadal trudne. Jako użytkownik widzisz tylko te programy, które zostały ukończone, a nie te, które się nie udały. W 2009 roku prawie jedna trzecia wszystkich projektów informatycznych odniosła sukces, podczas gdy prawie jedna czwarta nie powiodła się całkowicie lub została anulowana przed dostarczeniem oprogramowania. Pozostałe projekty zostały zakończone z opóźnieniem, przekroczyły budżet lub brakowało funkcjonalności. Słynną niedawną porażką projektu informatycznego było oprogramowanie systemu obsługi bagażu na nowym lotnisku w Denver. System okazał się bardziej złożony, niż spodziewali się tego inżynierowie; w końcu całe lotnisko było gotowe, ale musiało czekać 16 miesięcy na otwarcie, ponieważ oprogramowanie do systemu bagażowego nie działało. Lotnisko traciło milion dolarów dziennie podczas tych 16 miesięcy!
W tym rozdziale przyjrzymy się podstawom inżynierii oprogramowania. Wprowadzony zostanie temat analizy problemu, który pozwoli poznać rodzaj oprogramowania, jaki należy zbudować; omówimy pokrótce, jak zaprojektować i zbudować oprogramowanie, a następnie poświęcimy nieco czasu testowaniu oprogramowania, które jest jednym z najważniejszych kroków, w celu uniknięcia błędów. Jak widać poniżej, analiza, projektowanie i testowanie to ważne kroki przy tworzeniu oprogramowania. Właściwe programowanie zajmuje zwykle tylko 20% czasu w projekcie (w tym rozdziale prawie nie będziemy o tym wspominać)!
-
Dla ciekawych. Więcej informacji o błędach w oprogramowaniu
O ile każdy chce aby jego projekt się powiódł, na błędach można się wiele nauczyć! Oto niektóre strony, które dostarczają dalszych materiałów (po angielsku) na ten temat.
- CS4FN -- Z powrotem do tablicy projektowej
- IEEE -- Dlaczego oprogramowanie zawodzi
- IEEE -- Uczenie się na błędach oprogramowania
- Katastrofy inżynieryjne 13: Błędy w oprogramowaniu jest fragmentem odcinka 13 cyklu „Katastrofy inżynieryjne” tłumaczącego błędy w oprogramowaniu rakiety Ariane 5 i pocisków Patriot.
Aby móc zacząć tworzyć oprogramowanie, musimy wcześniej zdecydować, co chcemy właściwie osiągnąć. Ten etap projektu będziemy nazywać analizą, ponieważ dokładnie analizujemy, co nasze oprogramowanie musi robić. Chociaż brzmi to banalnie, sformułowanie wszystkich wymagań jest dość trudne. Gdyby ktoś poprosił cię o zaprojektowanie obiektu fizycznego, takiego jak krzesło lub toster, prawdopodobnie dobrze byś wiedział, jaki będzie gotowy produkt. Bez względu na to, ile nóg zdecydujesz się wprawić swemu krzesłu, nadal będzie musiał utrzymać osobę. Podczas projektowania oprogramowania często nie mamy możliwości tworzenia znanych obiektów, a często nawet nie znamy ograniczeń, takich jak prawa fizyki. Jeśli twoje oprogramowanie miałoby być, powiedzmy, programem pomagającym autorom wymyślać wyimaginowane światy, od czego byś zaczął? Co możesz uznać za pewnik?
Analiza jest niezmiernie istotna. Oczywiście, jeśli popełnimy błąd na tym etapie projektu, to powstanie oprogramowanie, które nie spełnia oczekiwań; wszystkie inne prace związane z projektowaniem, budowaniem i testowaniem oprogramowania mogą być spisane na straty.
Na przykład, wyobraź sobie, że twoja przyjaciółka Anna prosi cię o napisanie programu, który pomoże jej dostać się rano do szkoły. Piszesz świetny system nawigacji GPS i pokazujesz to Annie, ale okazuje się, że ona jeździ do szkoły autobusem. Zatem to, czego naprawdę potrzebowała, to oprogramowanie pokazujące aktualny rozkład jazdy autobusów. Cała twoja ciężka praca była daremna, ponieważ nie wydobyłeś odpowiednich informacji na samym początku!
Czasami tworzymy oprogramowanie na własne potrzeby; w takim przypadku możemy po prostu zdecydować, co powinien robić program. Bądź jednak ostrożny: nawet jeśli myślisz, że wiesz, co ma robić oprogramowanie, gdy zaczniesz je tworzyć, prawdopodobnie zmienisz zdanie na temat jego funkcjonalności. Wynika to z faktu, że pewne wymagania zauważamy dopiero, gdy zaczniemy korzystać z programu. Na przykład ludzie produkujący smartfony i oprogramowanie dla smartfonów prawdopodobnie nie przewidzieli, ile osób będzie chciało użyć telefonu jako latarki!
W wielu przypadkach tworzymy oprogramowanie dla innych osób. Możesz stworzyć stronę sklepu odzieżowego cioci lub napisać oprogramowanie, które pomoże twoim przyjaciołom w odrabianiu lekcji z matematyki. Firma produkująca oprogramowanie może tworzyć oprogramowanie dla lokalnej rady miejskiej lub lekarza rodzinnego. Google i Microsoft tworzą oprogramowanie używane przez miliony ludzi na całym świecie. Tak czy inaczej, niezależnie od tego, czy piszesz program dla swoich przyjaciół, czy dla milionów ludzi, najpierw musisz dowiedzieć się od swoich klientów, czego naprawdę potrzebują.
Każdego, kto jest zainteresowany oprogramowaniem będziemy nazywać interesariuszem (ang. stakeholder). Są to osoby, z którymi należy prowadzić dialog podczas analizy projektu, w celu uzyskania listy wymagań.
Wyobraź sobie, że tworzysz aplikację mobilną, która umożliwia uczniom zdalne zamawianie jedzenia w szkolnej stołówce. Mogą korzystać z aplikacji, aby poprosić o jedzenie rano, a następnie po prostu iść i odebrać jedzenie w porze obiadu. Chodzi o pomoc w organizacji wydawania posiłków i zmniejszeniu kolejek w stołówce. Oczywistymi interesariuszami dla twojego projektu są uczniowie (którzy będą korzystali z aplikacji na telefon) i pracownicy stołówki (którzy będą otrzymywać zamówienia za pośrednictwem aplikacji). Mniej oczywistymi (i pośrednimi) interesariuszami są rodzice („muszę kupić mojemu dziecku smartfon, aby mogło korzystać z tej aplikacji?”), administrator szkoły („telefonów nie powinno się używać na terenie szkoły!”). Różni interesariusze mogą mieć bardzo różne pomysły na funkcjonalność aplikacji.
Aby dowiedzieć się, czego potrzebują interesariusze, zwykle przeprowadzamy rozmowę. Zadajemy im pytania, aby znaleźć wymagania funkcjonalne i pozafunkcjonalne dla oprogramowania. Wymagania funkcjonalne to czynności, które oprogramowanie musi wykonać. Na przykład aplikacja mobilna musi umożliwiać uczniom wybór żywności, którą chcą zamówić. Następnie powinna wysłać zamówienie do stołówki wraz z nazwiskiem ucznia, aby można go było łatwo zidentyfikować podczas odbioru posiłku.
Z kolei, wymagania pozafunkcjonalne nie mówią nam co program ma robić, ale jak ma to robić (użwywamy pojęcia wymagania pozafunkcjonalne, które jest nieco nieprecyzyjne, ale jest powszechnie stosowane). Jak wydajny musi być? Jak niezawodny? Jakiego komputera (lub telefonu) trzeba, aby go uruchomić? Jak łatwy w użyciu powinien być?
W pierwszej kolejności musimy ustalić, kim są nasi interesariusze. Następnie przeprowadzamy z nimi rozmowy, aby znaleźć wymagania dotyczące programu. To pewnie nie wydaje się trudne, prawda? Niestety, komunikacja z klientem często okazuje się najtrudniejsza.
Pierwszy problem polega na tym, że klienci i programiści często nie mówią tym samym językiem. Oczywiście nie mamy na myśli, że nie mówią po polsku, lecz to, że informatycy używają języka technicznego, podczas gdy klienci używają języka specyficznego dla ich branży. Na przykład lekarze mogą używać wielu przerażających terminów medycznych, których nie zrozumiesz.
Wyobraź sobie, że jesteś poproszony o opracowanie systemu punktacji dla (fikcyjnej) dyscypliny sportowej szurany fikmik. Klient mówi: „To naprawdę proste. Trzeba tylko zapisywać fiki, lecz nie miki, chyba że szuracz krąży”. Po tym opisie jesteś prawdopodobnie bardzo zdezorientowany, ponieważ nie wiesz nic o sporcie szurany fikmik i nie znasz konkretnych terminów. Aby zacząć, powinieneś wziąć udział w kilku grach Whacky-Flob i obserwować, jak przebiega gra i jaka jest punktacja. W ten sposób będziesz w stanie więcej wydobyć z klienta, ponieważ masz pewną wiedzę na temat problemu. (Nawiasem mówiąc, jest to jedna z najfajniejszych rzeczy związanych z byciem programistą: masz kontakt z różnymi, ekscytującymi problemami: w jednym projekcie możesz śledzić niedźwiedzie grizzly, w następnym identyfikować cyberterrorystów lub sprawiać, że samochód sam jeździ.)
Nie należy również zakładać, że klient zna techniczne pojęcia, takie jak JPEG, baza danych, a może nawet system operacyjny. Stwierdzenie „Hierarchia podklasy metaklasy była ograniczona, aby być analogiczna do hierarchii klas i podklas, które są ich instancjami” może mieć sens dla programisty, ale klient będzie po prostu patrzeć na ciebie bardzo zdezorientowany! Jeden z autorów wziął kiedyś udział w spotkaniu z klientem, w którym zapytano zainteresowanego, czy chce korzystać z systemu za pośrednictwem przeglądarki. Niestety klient nie miał pojęcia, czym jest przeglądarka. Czasami klienci mogą nie chcieć przyznać, że nie mają pojęcia o czym mówisz i po prostu powiedzieć „tak”. Pamiętaj, że to ty jesteś odpowiedzialny za to, że rozumiecie się z klientem i że odpowiedzi od klienta są przydatne!

Nawet jeśli uda Ci się porozumieć z klientami, może się okazać, że tak naprawdę nie wiedzą, co chcą zrobić lub nie mogą tego wyrazić. Mogą powiedzieć, że chcą oprogramowania, które „usprawni ich działalność” lub „sprawi, że ich praca będzie bardziej wydajna”. (Jest świetny rysunek z z serii Dilbert, który ilustruje ten punkt!) Kiedy pokazujesz klientom oprogramowanie, które zbudowałeś, zazwyczaj nie jest im trudno ocenić, czy tego właśnie chcieli, co im się w nim podoba, a co nie. Z tego powodu warto tworzyć małe prototypy podczas opracowywania systemu i wyświetlać je klientom, aby uzyskać od nich informacje zwrotne.
Często się zdarza, że klienci mają specyficzne przyzwyczajenia i chcą, aby oprogramowanie dopasowało się do tego. Byliśmy kiedyś zaangażowani w projekt wykonywany przez studentów na potrzeby biblioteki. Personel zapisywał informacje o wypożyczonych książkach trzykrotnie na papierowym formularzu, rozcinał formularz i wysyłał części w różne miejsca jako dokument do przechowywania. Kiedy studenci wypytywali pracowników biblioteki o wymagania, zostali poproszeni o okienko w aplikacji, w którym mogliby wprowadzić informacje również trzy razy (pomimo tego, że w systemie informatycznym nie ma to większego sensu)!
Klienci są zwykle ekspertami w swojej dziedzinie i dlatego mogą pominąć informacje, które ich zdaniem są oczywiste, ale mogą nie być oczywiste dla programisty. Innym razem nie rozumieją, co można i czego nie można zrobić przy pomocy komputera i mogą nie wspomnieć o czymś, ponieważ nie zdają sobie sprawy, że można to zrobić za pomocą komputera. Od ciebie zależy, czy otrzymasz od nich istotne informacje.

-
Ciekawostka. Łatwe dla komputerów i trudne dla ludzi, a trudne dla komputerów i łatwe dla ludzi
Tekst ukazujący się po najechaniu myszką na powyższy rysunek (wygodniej przeczytać go na stronie xkcd) jest również wart przeczytania. Rozpoznawanie obrazów to problem, który początkowo wydawał się prosty, prawdopodobnie dlatego, że ludzie uważają to za łatwe. Interesujące jest to, że wiele problemów jest łatwych dla komputerów, chociaż wydają się trudne dla ludzi. Na przykład pomnożenie dwóch dużych liczb. Z drugiej strony, istnieje wiele innych problemów, których komputery nie potrafią rozwiązać, natomiast dla ludzi nie stanowią one problemu, na przykład rozpoznanie, że zdjęcie przedstawia kota.
Jeśli projekt dotyczy wielu interesariuszy, mogą pojawić się sprzeczne punkty widzenia. Na przykład, gdy rozmawiasz z ludźmi ze stołówki o aplikacji do zamawiania posiłków, mogą zażądać, by maksymalna wartość zamówienia wynosiła 20 zł. W ten sposób mogą uniknąć niepoważnych zamówień. Nauczyciele mogą zgodzić się z tą sugestią. Nie chcą, aby jakiś uczeń był zastraszany przez kolegów i zmuszany do kupowania im (zdalnie) jedzenia. Uczniowie z kolei będą twierdzić, że chcą zamówić jedzenie dla swoich przyjaciół. Ich zdaniem limit 20 zł nie wystarcza nawet dla jednego ucznia.
Co zrobisz z tymi sprzecznymi punktami widzenia? W tym przypadku potrzebujesz poparcia ze strony stołówki i nauczycieli, aby Twoje oprogramowanie działało, ale może uda ci się wynegocjować nieco wyższy limit zamówień wynoszący 40 zł, aby spróbować zadowolić wszystkich swoich interesariuszy.
Jednak, nawet jeśli zrobisz porządną analizę projektu, porozmawiasz ze wszystkimi interesariuszami i ustalisz wszystkie wymagania dotyczące oprogramowania, wymagania mogą ulec zmianie podczas tworzenia oprogramowania. Wykonanie dużych projektów może trwać latami. Wyobraź sobie, ile zmian w świecie technologii ma miejsce w ciągu roku! Podczas pracy nad projektem może pojawić się nowy sprzęt (telefony, komputery, tablety, …) lub konkurencja może wypuścić oprogramowanie bardzo podobne do tego, co robisz. Twoje oprogramowanie może również zmienić sytuację na rynku: po dostarczeniu oprogramowania klient spróbuje z nim pracować i może odkryć, że to nie jest to, czego naprawdę chciał. Dlatego nigdy nie powinieneś zakładać, że wymagania będą ustalone raz na zawsze. Najlepiej byłoby regularnie rozmawiać z klientami podczas całego projektu i zawsze być gotowym na zmianę wymagań!
-
Projekt. Ustalanie wymagań
W przypadku tego projektu musisz znaleźć kogoś, dla kogo mógłbyś wykonać oprogramowanie. Może to być ktoś z twojej rodziny lub przyjaciel. Mogą na przykład potrzebować oprogramowania do zarządzania informacjami o klientach swoich firm lub klubu szachowego, co może wymagać oprogramowania do planowania turniejów szachowych lub pomóc w ustalaniu harmonogramu treningów. (W przypadku tego projektu tak naprawdę nie będziesz tworzyć oprogramowania, tylko ustalać wymagania. Jeśli projekt jest na tyle mały, że możesz go samemu zaprogramować, prawdopodobnie nie jest wystarczająco duży, żeby być dobrym przykładem dla inżynierii oprogramowania!)
Po znalezieniu tematu dla projektu zacznij od zidentyfikowania i opisania interesariuszy. (Projekt będzie najbardziej pouczający, jeśli masz co najmniej dwóch różnych interesariuszy.) Spróbuj ustalić wszystkich interesariuszy, pamiętając, że niektórzy z nich mogą być jedynie pośrednio zainteresowani twoim oprogramowaniem. Na przykład, jeśli tworzysz bazę danych do przechowywania informacji o klientach, klienci, których dane są przechowywane, mogą być zainteresowani twoim oprogramowaniem, nawet jeśli nigdy nie używają go bezpośrednio; będą chcieli, aby oprogramowanie było bezpieczne, aby ich dane nie mogły zostać skradzione. Stwórz opis każdego interesariusza, podając jak najwięcej szczegółów. Kim oni są? Jakie cele mogą uzyskać dzięki oprogramowaniu? Jaką mają wiedzę techniczną? …
Przepytaj jednego z interesariuszy, aby dowiedzieć się, jakie są jego oczekiwania odnośnie oprogramowania. Zapisz wymagania dotyczące oprogramowania, podając pewne szczegóły dotyczące każdego z nich. Spróbuj rozróżnić wymagania funkcjonalne i pozafunkcjonalne. Upewnij się, że wiesz, jakie rzeczy są dla niego najważniejsze. W ten sposób możesz nadać każdemu wymaganiu priorytet (na przykład wysoki, średni, niski), byś mógł -- gdybyś faktycznie zaczął realizować projekt -- zacząć od najważniejszych funkcji.
Spróbuj wyobrazić sobie, jakie byłyby ich wymagania dla pozostałych interesariuszy. W szczególności spróbuj ustalić, czym ich wymagania różnią się od wymagań innych interesariuszy. Możliwe, że dwóch interesariuszy ma te same wymagania, ale czy mogą mieć różne priorytety dla każdego z nich? Sprawdź, czy możesz wymienić potencjalne rozbieżności lub konflikty między zainteresowanymi stronami? Jeśli tak, to jak byś je rozwiązał?
Kiedy już zdecydujesz, co twoje oprogramowanie ma robić, możesz je zaprojektować. Zaczynanie projektu „na ślepo” może wpędzić cię w kłopoty; pamiętaj, że większość oprogramowania jest ogromna i bardzo złożona. Musisz jakoś zminimalizować złożoność oprogramowania, inaczej kod programu stanie się niemożliwy do zrozumienia i rozwijania przez innych programistów w przyszłości.
Projektowanie oprogramowania sprowadza się do zarządzania jego złożonością i ciągłego upewniania się, że tworzone przez nas oprogramowanie ma dobrą strukturę. Zanim zaczniemy pisać dowolny kod, projektujemy strukturę naszego oprogramowania. Kiedy mówisz o projektowaniu oprogramowania, wiele osób pomyśli, że mówisz o projektowaniu wyglądu oprogramowania. Tutaj zajmiemy się zaprojektowaniem wewnętrznej struktury oprogramowania.
Zatem w jaki sposób możemy zaprojektować oprogramowanie, aby nie stało się ono niezwykle złożone i niemożliwe do zrozumienia? Poniżej przedstawiamy dwa ważne podejścia: poddział i abstrakcję. To dość przerażające słowa, ale jak się wkrótce przekonasz, pojęcia za nimi stojące są zaskakująco proste.
Prawdopodobnie domyślasz się co oznacza pojęcie podział: Rozbijamy oprogramowanie na wiele mniejszych części, które można zbudować niezależnie. Każda mniejsza część może zostać podzielona na jeszcze mniejsze części i tak dalej. Jak wspomnieliśmy we wstępie, wiele programów jest tak dużych i złożonych, że jedna osoba nie może tego wszystkiego pojąć; możemy łatwiej poradzić sobie z mniejszymi częściami. Złożone oprogramowanie jest tworzone przez duże zespoły, tak aby różne osoby mogły pracować nad różnymi częściami i rozwijać je równolegle, niezależnie od siebie. Na przykład, w przypadku projektu dla stołówki, możesz pracować nad stworzeniem bazy danych, która rejestruje, jakie jedzenie sprzedaje stołówka i ile kosztuje każdy artykuł, podczas gdy twój przyjaciel pracuje nad rzeczywistą aplikacją mobilną, którą uczniowie będą używać do zamawiania jedzenia.
Po opracowaniu wszystkich części programu musimy sprawić, aby komunikowały się ze sobą. Jeśli różne części zostały dobrze zaprojektowane, jest to stosunkowo łatwe. Każda część ma tak zwany interfejs, z którym inne części mogą się komunikować. Na przykład, twoja część projektu stołówkowego powinna zapewnić sposób przekazywania innym częściom informacji o tym, jakie jedzenie jest oferowane i ile kosztuje. Dzięki temu twój kolega, który pracuje nad aplikacją dla uczniów, może po prostu wysłać prośbę do twojej części i uzyskać te informacje. Nie musi dokładnie wiedzieć, jak działa twoja część systemu; powinen po prostu wysyłać prośby i ufać, że odpowiedź, którą otrzymają od twojej strony jest poprawna. W ten sposób każda osoba pracująca nad projektem musi jedynie wiedzieć, jak działa jego własna część oprogramowania.
Porozmawiajmy o drugim pojęciu, abstrakcji. Czy zastanawiałeś się kiedyś, dlaczego możesz prowadzić samochód, nie wiedząc, jak działa jego silnik? Albo jak możesz korzystać z komputera bez wiedzy o sprzęcie? Może wiesz, czym jest procesor i dysk twardy, ale czy możesz zbudować własny komputer? Czy twoi rodzice potrafiliby? Dzięki abstrakcji nie musimy dokładnie wiedzieć, jak komputery lub samochody działają w środku, aby móc z nich korzystać!
Jeśli przyjrzymy się bliżej komputerowi, to zauważymy, że w rzeczywistości ma on kilka warstw abstrakcji. Na najniższym poziomie mamy sprzęt, w tym procesor, pamięć RAM, dysk twardy i różne skomplikowane układy scalone, kable i wtyczki.
Po uruchomieniu komputera zaczyna uruchamiać się system operacyjny. System operacyjny jest odpowiedzialny za komunikację ze sprzętem, zwykle za pomocą specjalnego oprogramowania, zwanego sterownikami. Po uruchomieniu komputera możesz uruchamiać programy, na przykład przeglądarkę. Przeglądarka nie komunikuje się bezpośrednio ze sprzętem, ale za pośrednictwem systemu operacyjnego.
Wreszcie, najwyższą warstwą systemu jest użytkownik. Korzysta z programu, ale raczej nie musi wchodzić w interakcje z bardziej skomplikowanymi częściami systemu operacyjnego, takimi jak oprogramowanie sterownika, nie wspominając już o sprzęcie. W ten sposób możemy korzystać z komputera, nie martwiąc się o to, jak on działa na niższych poziomach.
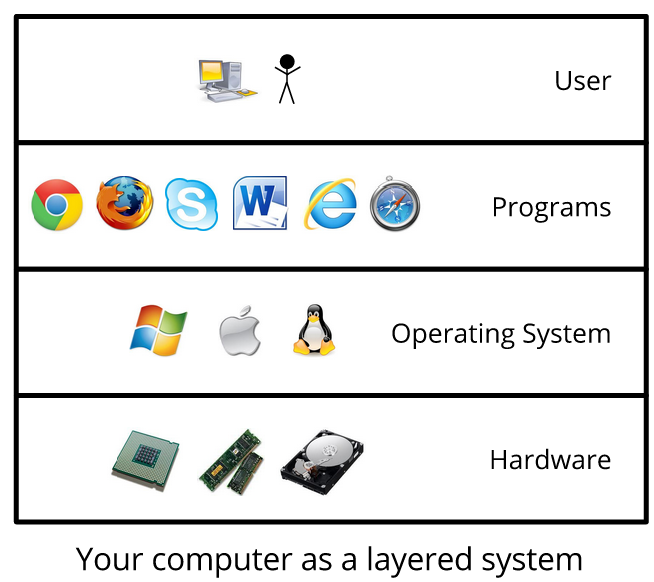
Komputer można podzielić na wiele warstw, zaczynając od użytkownika, programów, systemu operacyjnego oraz sprzętu.
System taki nazywamy systemem warstwowym. Może mieć dowolną liczbę warstw, ale każda warstwa może komunikować się tylko z tą znajdującą się bezpośrednio pod nią. System operacyjny może uzyskać bezpośredni dostęp do sprzętu, ale program działający na komputerze nie może tego zrobić. Możesz używać programów, ale miejmy nadzieję, że nigdy nie będziesz musiał uzyskać dostępu do sprzętu lub bardziej złożonych części systemu operacyjnego, takich jak sterowniki. To dodatkowo zmniejsza złożoność systemu, ponieważ każda warstwa musi „wiedzieć” tylko o warstwie bezpośrednio pod nią, a nie o innych.
Każda warstwa w systemie musi jedynie zapewnić interfejs, aby warstwa nad nim mogła za jego pomocą przesyłać komunikaty. Na przykład procesor dostarcza zestaw instrukcji dla systemu operacyjnego; system operacyjny udostępnia polecenia programom do tworzenia lub usuwania plików na dysku twardym; program udostępnia przyciski i polecenia, dzięki czemu można z nim wejść w interakcję.
Dana warstwa nie wie nic o wewnętrznych działaniach warstwy poniżej; musi tylko wiedzieć, jak korzystać z interfejsu warstwy. W ten sposób złożoność niższych warstw jest całkowicie ukryta lub wyabstrahowana. Każda warstwa reprezentuje wyższy poziom abstrakcji.
Każda warstwa ukrywa swoją złożoność, więc gdy przechodzimy przez kolejne poziomy, wszystko wydaje się możliwe do zarządzania. Kolejną zaletą posiadania warstw jest to, że możemy zmienić jedną warstwę bez wpływu na pozostałe, o ile oczywiście zachowamy interfejs warstwy. Na przykład kod przeglądarki może się zmienić, ale możesz tego nie zauważyć, dopóki przeglądarka nadal wygląda i działa tak samo jak poprzednio. Oczywiście, jeśli przeglądarka przestanie działać lub nagle pojawią się nowe przyciski, to odczujesz zmiany.
Możemy zastosować podobne „warstwowe” podejście w ramach jednego programu. Na przykład strony internetowe są często projektowane jako tzw. trójwarstwowe systemy składające się z: warstwy bazy danych, warstwy logiki i warstwy prezentacji. Warstwa bazy danych zwykle odpowiada za przechowywanie informacji, których potrzebuje strona internetowa. Na przykład Facebook ma ogromną bazę danych, w której przechowuje informacje o swoich użytkownikach. Dla każdego użytkownika przechowuje informacje o tym, kim są jego znajomi, jakie wiadomości opublikowali, jakie zdjęcia dodali itd. Warstwa logiczna przetwarza dane, które pobiera z bazy danych. Warstwa logiki Facebooka, na przykład, zdecyduje, które posty mają być wyświetlane na twoim "domowym" kanale, których użytkowników zasugerować jako nowych znajomych, itp. Na koniec warstwa prezentacji pobiera informacje z warstwy logicznej i je wyświetla. Zwykle warstwa prezentacji nie przetwarza dodatkowo informacji, które dostaje, ale po prostu generuje stronę HTML.
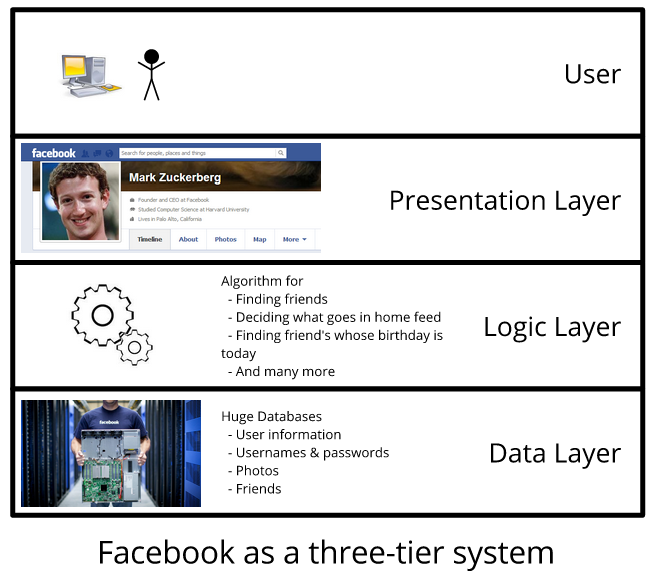
Facebook można rozpatrywać jako system trzywarstwowy, składający się z warstwy prezentacji, warstwy logicznej oraz warstwy danych.
-
Ciekawostka. Ponowne użycie -- kangury i helikoptery
Ponieważ budowanie oprogramowania jest tak trudne i czasochłonne, popularnym rozwiązaniem stało się ponowne wykorzystanie istniejącego oprogramowania. Nie będzie zaskoczeniem, że tę praktykę będziemy nazywać ponownym użyciem oprogramowania. Teoretycznie jest to świetny sposób postępowania (dlaczego tworzyć coś od nowa, skoro już istnieje?), lecz okazuje się trudny do zastosowania w praktyce. Wynika to z faktu, że istniejące oprogramowanie jest również ogromne i skomplikowane. Zwykle, gdy ponownie używasz oprogramowania, potrzebujesz tylko niewielkiej części funkcjonalności istniejącego oprogramowania, a nie wszystkiego.
Ciekawa historia ilustrująca problemy z ponownym użyciem oprogramowania to helikoptery i kangury (chociaż nie jest to idealna analogia, zobacz tu). Australijskie lotnictwo opracowało nowy symulator śmigłowca do szkolenia pilotów. Chcieli, aby symulator był jak najbardziej realistyczny, dlatego postanowili uwzględnić stada kangurów w symulacji. Aby zaoszczędzić czas, wykorzystali kod z innego symulatora, który obejmował żołnierzy piechoty i po prostu zmienili ikony żołnierzy na kangury.
Po zakończeniu pracy nad programem zademonstrowali to grupie pilotów. Jeden z nich postanowił polecieć helikopterem blisko stada kangurów, aby zobaczyć, co się stanie. Kangury rozproszyły się, by się ukryć, a następnie, ku zdziwieniu pilota, wyciągnęły karabiny i wyrzutnie pocisków, z których zaczęły strzelać w kierunku śmigłowca. Wyglądało na to, że programista zapomniał usunąć ten fragment kodu z oryginalnego symulatora.
-
Projekt
Wróć do wymagań, które znalazłeś w opisanej powyżej analizie. W tym projekcie przyjrzymy się temu, jak projektowane jest oprogramowanie.
Zacznij od zastanowienia się jak możesz podzielić oprogramowanie, które masz zamiar zbudować, na mniejsze części. Może zawiera bazę danych lub interfejs użytkownika, lub stronę internetową? Na przykład wyobraź sobie, że piszesz oprogramowanie do sterowania robotem. Robot musi używać czujników, aby podążać za czarną linią wyznaczoną na podłodze, aż dotrze do celu. Oprogramowanie twojego robota powinno mieć część, która współdziała z czujnikami, aby uzyskać informacje o tym, co „widzą”. Powinien następnie przekazać tę informację do innej części, która analizuje dane i decyduje, dokąd dalej się poruszać. Na koniec powinieneś mieć część oprogramowania, która współdziała z kołami robota, aby poruszać się w określonym kierunku.
Spróbuj podzielić oprogramowanie na jak najwięcej części (pamiętaj, małe komponenty są łatwiejsze do zbudowania!). Ale nie idź zbyt daleko -- każda część powinna wykonać sensowne zadania i być względnie niezależna od reszty systemu.
Dla każdej zidentyfikowanej części programu napisz krótki opis tego, co robi. Następnie pomyśl, w jaki sposób poszczególne części będą wchodzić w interakcje. Dla każdej części, odpowiedz sobie pytanie, z jakimi innymi częściami potrzebuje się bezpośrednio komunikować. Może diagram może pomóc w wizualizacji tego?
Zdecydowaliśmy, co powinno robić nasze oprogramowanie (analiza) i zaprojektowaliśmy jego wewnętrzną strukturę (projekt), a system został zaprogramowany zgodnie z projektem. Teraz oczywiście musimy go przetestować, aby upewnić się, że działa poprawnie.
Testowanie jest niezwykle ważnym elementem tworzenia oprogramowania. Nie możemy przecież wypuścić oprogramowania, które wciąż będzie wyświetlało klientom komunikaty o błędach. (Cóż, moglibyśmy, ale nasi klienci nie byliby z tego raczej zadowoleni.) Pamiętaj, że błędy w oprogramowaniu mogą mieć zarówno bardzo małe, jak i bardzo duże konsekwencje. Z jednej strony mogą utrudnić korzystanie z programu lub spowodować awarię komputera. Z drugiej strony mogą kosztować miliony dolarów, a nawet zagrażać ludzkiemu życiu. Więcej testów mogło zapobiec awarii rakiety Ariane 5 lub mogło pozwolić wykryć błąd w oprogramowaniu maszyny Therac, który spowodował śmierć trzech pacjentów.
Niestety, ze względu na rozmiar i złożoność oprogramowania, testowanie jest również trudnym zadaniem. Jeśli przeczytanie i zrozumienie jakiegoś oprogramowania zajęłoby lata, wyobraź sobie, ile czasu zajęłoby jego pełne przetestowanie!
Kiedy testujemy oprogramowanie, wypróbowujemy wiele różnych danych wejściowych i widzimy, jakie jest zachowanie programu. Jeśli wynik jest niepoprawny, znaleźliśmy błąd.
-
Ciekawostka. Błędy i ćmy

Komputer Mark II na Harvardzie
W 1947 roku inżynierowie pracujący na komputerze o nazwie Mark II badali błąd komputera i odkryli, że został spowodowany przez ćmę, która została uwięziona wewnątrz komputera! Ten incydent jest wczesnym przykładem użycia słowa bug (po polsku: robak, ćma lub pluskwa) w odniesieniu do błędów komputera. Oczywiście dzisiaj używamy tego słowa, aby odnieść się do błędów w programach, a nie do rzeczywistych owadów uwięzionych w komputerze.
Problem z testowaniem polega na tym, że możemy wykazać tylko obecność błędów, a nie ich brak! Jeśli otrzymasz niepoprawne dane wyjściowe z programu, wiesz, że znalazłeś błąd. Lecz jeśli otrzymasz poprawne wyniki, czy naprawdę możesz być pewien, że program jest poprawny? Nie do końca. Oprogramowanie może działać poprawnie w tym konkretnym przypadku, ale nie można zakładać, że zadziała w innych sytuacjach. Bez względu na to, jak dokładnie testujesz program, nigdy nie możesz być w 100% pewny, że jest on poprawny. Teoretycznie musisz przetestować każdy możliwy zestaw danych wejściowych, ale zazwyczaj nie jest to możliwe. Wyobraź sobie, że testujemy wyszukiwarkę Google pod względem wszystkich możliwych zapytań, które mogą zadać ludzie! Jeśli nawet nie możemy przetestować wszystkiego, zawsze możemy wypróbować jak najwięcej różnych przypadków testowych i mieć nadzieję, że w ten sposób zmniejszyliśmy prawdopodobieństwo wystąpienia błędów.
Podobnie jak w przypadku projektowania, nie jesteśmy w stanie poradzić sobie z całym oprogramowaniem naraz, więc ponownie przyglądamy się mniejszym elementom, testując każdy z nich z osobna. To podejście nazywamy testowaniem jednostkowym. Test jednostkowy jest zwykle wykonywany przez oddzielny program, który uruchamia testy. W ten sposób możesz przeprowadzać testy tak często, jak chcesz -- być może raz dziennie lub za każdym razem, gdy następuje zmiana w programie.
Nie jest niczym niezwykłym napisanie testów jednostkowych przed napisaniem danego fragmentu programu. Może się wydawać daremną pracą pisanie dwóch programów zamiast jednego, ale możliwość sprawdzenia systemu dokładnie po każdej zmianie znacznie poprawia niezawodność produktu końcowego i może zaoszczędzić wiele czasu na szukaniu błędów w całym systemie. Testy jednostkowe zwiększają pewność, że każdy element działa poprawnie.
Po dokładnym przetestowaniu wszystkich oddzielnych elementów możemy przetestować cały system, aby sprawdzić, czy wszystkie części współpracują ze sobą prawidłowo. Testy tego typu nazywa się testami integracyjnymi. Niektóre testy tego typu mogą być zautomatyzowane, inne z kolei mogą być wykonywane ręcznie.
Jeśli otrzymałbyś część oprogramowania do przetestowania, jak byś zaczął? Które z danych testowych użyłbyś jako dane wejściowe? Ile różnych przypadków testowych potrzebujesz? Kiedy poczujesz się dość pewny, że wszystko działa poprawnie?
Istnieją dwa podstawowe podejścia, które nazywamy testami czarnej skrzynki i testami białej skrzynki. Przy testowaniu metodą czarnej skrzynki traktujesz po prostu program jak czarną skrzynkę i udajesz, że nie wiesz, jak jest zbudowany i jak działa wewnętrznie. Dajesz mu testowe dane, otrzymujesz wyniki i sprawdzasz, czy program działa zgodnie z oczekiwaniami.
Ale jak wybrać dobre dane testowe? Zwykle jest bardzo dużo możliwości do wyboru. Na przykład, wyobraź sobie, że jesteś proszony o przetestowanie programu, który przyjmuje liczbę całkowitą i zwraca liczbę następną w kolejności (np. dla 3, a otrzymasz 4, dla -10 wynikiem będzie -9, itd.). Nie możesz wypróbować programu dla wszystkich liczb, więc które z nich wypróbujesz?
Zauważ, że wiele liczb jest podobnych i jeśli program działa dla jednej z nich, to prawdopodobnie będzie działał dla innych. Na przykład, jeśli program działa zgodnie z oczekiwaniami, gdy podajesz mu liczbę 3, to prawdopodobnie jest stratą czasu testowanie liczb 4, 5, 6.
Jest to związane z pojęciem klas równoważności. Niektóre dane wejściowe są podobne pod pewnym względem. Powinieneś zatem wybrać tylko jednego lub dwóch podobnych reprezentantów do testowania, a następnie założyć, że jeżeli dla nich program działa poprawnie, to będzie również działał poprawnie dla podobnych do nich. W przypadku naszego programu istnieją dwie duże klasy równoważności, liczby dodatnie i liczby ujemne. Możesz także argumentować, że zero jest same w sobie osobną klasą równoważności, ponieważ nie jest ani dodatnie, ani ujemne.
Do testowania wybierzemy kilka danych wejściowych z każdej klasy równoważności. Wejścia na granicy klas równoważności są zwykle szczególnie interesujące. W tym przypadku powinniśmy zdecydowanie przetestować -1 (powinno dać 0), 0 (powinno dać 1) i 1 (powinno dać 2). Powinniśmy także wypróbować inną ujemną i dodatnią bardziej oddaloną od granicy, na przykład -48 i 57. Wreszcie, może być interesujące wypróbowanie bardzo dużych liczb, więc weźmy -2 338 678 i 10 462 873. Przetestowaliśmy tylko 7 różnych wejść, ale te wejścia prawdopodobnie pokryją większość interesujących zachowań naszego programu i powinny ujawnić większość błędów.
Oczywiście możesz również spróbować wypróbować nieprawidłowych danych wejściowych, na przykład „cześć” (słowo) lub „1,234” (liczba z przecinkiem) lub „1.234” (liczba z kropką dziesiętną). Często takie przypadki testowe mogą powodować, że programy zachowują się w bardzo dziwny sposób, mogą nawet ulec awarii. Programista nie przewidział, że program może otrzymać nieprawidłowe dane wejściowe. Pamiętaj, że szczególnie ludzcy użytkownicy mogą dać ci różnego rodzaju dziwne dane wejściowe, na przykład jeśli źle zrozumieli, w jaki sposób program powinien zostać użyty. W przypadku nieprawidłowego wejścia prawdopodobnie chcesz, aby program poinformował użytkownika, że dane wejściowe są nieprawidłowe; na pewno nie chcesz, aby się zawiesił!
Testowanie metodą czarnej skrzynki (ang. black-box) jest łatwe, ale nie zawsze wystarczające. Wynika to z faktu, że czasami znalezienie klas równoważności może być trudne, szczególnie jeśli nie znasz wewnętrznej struktury programu. Kiedy wykonujemy testowanie w trybie białej skrzynki (ang. white-box), przyglądamy się kodowi, który testujemy, i wymyślamy testy, które spowodują wykonanie jak największej liczby wierszy kodu. Jeśli wykonamy każdy wiersz przynajmniej raz, powinniśmy być w stanie odkryć wiele błędów. Podejście to nazywamy pokryciem kodu i dążymy do 100% pokrycia tak, aby każdy wiersz kodu był uruchamiany co najmniej raz. Ponieważ jednen wiersz kodu może działać inaczej w zależności od danych wejściowych, to nawet 100% pokrycie kodu niekoniecznie wyeliminuje wszystkie błędy. Mimo wszystko jest to całkiem dobry początek zapewniania niezawodności.
Testy jednostkowe są bardzo użyteczne przy wyszukiwaniu błędów. Pomagają nam dowiedzieć się, czy program działa zgodnie z tym, jak my go zaprojektowaliśmy. Kolejnym ważnym pytaniem podczas testowania jest to, czy oprogramowanie robi to, czego oczekuje klient (czy zbudowaliśmy właściwą rzecz?). Testy akceptacyjne oznaczają demonstrowanie programu interesariuszom i uzyskiwanie informacji zwrotnych o tym, co im odpowiada, a co nie. Wszelkie błędy, które popełniliśmy na etapie analizy projektu, prawdopodobnie ujawnią się podczas testów akceptacyjnych. Jeśli podczas zbierania wymagań źle zrozumiemy klienta, oprogramowanie może przejść pomyślnie nasze testy jednostkowe (tzn. oprogramowanie robi to, co uważaliśmy za konieczne), ale wciąż możemy mieć niezadowolonego klienta.
Interesariusze mogą być bardzo zróżnicowani, na przykład pod względem umiejętności technicznych, a nawet mogą dostarczyć nam sprzeczne wymagania dotyczące oprogramowania. Możliwe jest zatem uzyskanie pozytywnych opinii od jednego z interesariuszy i negatywnych opinii od innych.
-
Projekt. Testy akceptacyjne
Jako projekt wybierz jeden z niewielkich dostępnych programów, taki jak aplikacja systemu Windows lub widget pulpitu Apple. Wybierz coś, co uznasz za szczególnie interesujące lub przydatne (np. zegar, stoper, słownik lub kalkulator). Zacznij od przeczytania opisu programu, aby dowiedzieć się, co robi przed jego wypróbowaniem.
Następnie zastanów się, jacy będą interesariusze dla tego oprogramowania. Kto by go użył i dlaczego? Krótko zanotuj kilka podstawowych informacji o każdym interesariuszu i jego głównych wymaganiach (jak w projekcie analitycznym). Zwróć uwagę na priorytety poszczególnych wymagań dla danego interesariusza.
Teraz możesz śmiało zainstalować program i pobawić się z nim. Spróbuj sobie wyobrazić, że jesteś interesariuszem, którego opisałeś powyżej. Postaw się na miejscu tej osoby. Jakie byłyby ich wrażenia z pracy z tym programem? Czy spełniłby ich wymagania? Jakie ważne funkcje są niedostępne? Spróbuj sprawdzić, czy możesz znaleźć jakieś konkretne problemy lub błędy w programie. (Podpowiedź: czasami wprowadzanie nieoczekiwanych danych wejściowych, na przykład słowo, gdy spodziewano się liczby, może spowodować pewne interesujące zachowanie).
Sporządź krótki raport z testu akceptacyjnego o tym, co znalazłeś. Spróbuj znaleźć powiązania z wymaganiami zapisanymi wcześniej, zaznaczając, które zostały spełnione (lub częściowo spełnione), a które nie. Czy uważasz, że interesariusz byłby zadowolony z oprogramowania? Czy myślisz, że chętnie by z niego korzystali? Jakie funkcje warto by dodać do programu?
Do tej pory dowiedziałeś się o różnych etapach rozwoju oprogramowania: analizie, projektowaniu i testowaniu. Ale w jaki sposób te fazy pasują do siebie? W jakim momencie pracy nad projektem wykonujemy daną czynność? Tym zagadnieniem zajmują się procesy tworzenia oprogramowania.
Oczywistą odpowiedzią byłoby rozpoczęcie od analizy, aby dowiedzieć się, co chcemy zbudować, następnie zaprojektowanie struktury oprogramowania, implementacja i ostatecznie testowanie. Jest to najprostszy proces, zwany modelem kaskadowym.
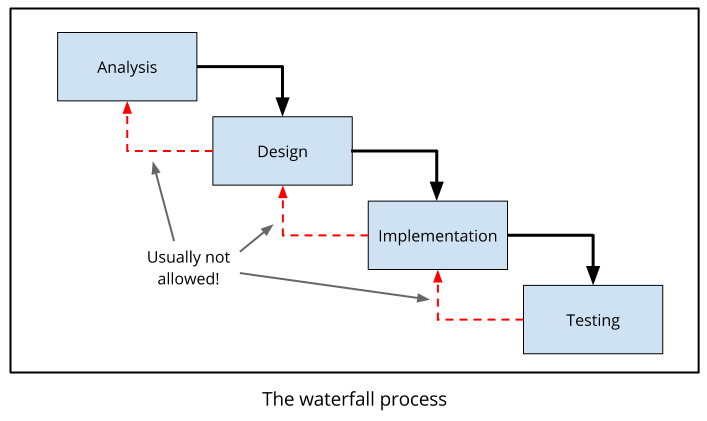
Model kaskadowy zapożyczono z innych działów inżynierii. Jeśli chcemy zbudować most, przechodzimy przez te same etapy analizy, projektowania, wdrażania i testowania: decydujemy, jakiego typu most potrzebujemy (jak długi i szeroki powinien być? Jakie obciążenie powinien wytrzymać?), projektujemy most, budujemy go i testujemy, zanim udostępnimy go publicznie. Tak było przez wiele dziesięcioleci i działa bardzo dobrze, przynajmniej w przypadku mostów.
Proces ten nazywamy kaskadowym, ponieważ po „przeskoku” z jednej fazy projektu do kolejnej nie można wrócić do poprzedniej. W rzeczywistości pewne drobne powroty, w celu usunięcia usterek fazy poprzedniej, się zdarzają, ale są raczej wyjątkiem. Jeśli podczas fazy testowania projektu nagle pojawi się problem z wymaganiami, na pewno nie będziesz mógł cofnąć się i poprawić wymagania.

Zaletą modelu kaskadowego jest to, że jest bardzo prosty i łatwy do przeprowadzenia. W dowolnym punkcie projektu bardzo jasne jest, na jakim etapie projektu się znajdujesz. Pomaga to również w planowaniu: jeśli jesteś na etapie testowania, wiesz, że jesteś już daleko w projekcie i wkrótce powinien się on zakończyć. Z tych powodów proces wodospadu jest bardzo popularny wśród menedżerów, którzy lubią poczucie kontroli nad tym, gdzie jest projekt i dokąd zmierza.
-
Ciekawostka. Prawo Hofstadtera
Twój menadżer i klient prawdopodobnie często będą pytać, ile czasu zajmie tobie projekt i kiedy ostatecznie stworzysz gotowy program. Niestety, naprawdę trudno jest przewidzieć, jak długo projekt będzie jeszcze trwał. Zgodnie z prawem Hofstadtera: „Projekt zawsze trwa dłużej niż się spodziewasz, nawet jeśli weźmiesz pod uwagę prawo Hofstadtera”. Uczenie się dokonywania dobrych oszacowań jest ważną częścią inżynierii oprogramowania.
Ponieważ jest prosty i przyjemny, model kaskadowy nadal znajduje się w wielu podręcznikach inżynierii oprogramowania i jest szeroko stosowany w przemyśle. Problem polega na tym, że nie działa on w przypadku większości projektów informatycznych.
Dlaczego zatem model kaskadowy nie działa w przypadku oprogramowania, podczas gdy sprawdza się dobrze w przypadku innych projektów inżynieryjnych, takich jak mosty (w końcu większość mostów wytrzymuje wiele lat...)? Przede wszystkim musimy pamiętać, że oprogramowanie bardzo różni się od mostów. Jest o wiele bardziej złożone. Zrozumienie planów pojedynczego mostu i jego działania może być możliwe dla jednej osoby. Tego samego nie da się powiedzieć o złożonych programach. Nie możemy łatwo spojrzeć na oprogramowanie jako całość (pomijając jego kod), aby zobaczyć jego strukturę. Kod nie jest fizyczny i dlatego nie przestrzega praw fizyki. Ponieważ oprogramowanie jest tak różne od innych produktów inżynieryjnych, tak naprawdę nie ma powodu, dla którego ten sam model powinien być stosowany w obu przypadkach.
Aby zrozumieć, dlaczego model kaskadowy nie działa, należy wrócić do podrozdziału dotyczącego analizy, pamiętając, jak trudno jest znaleźć odpowiednie wymagania dotyczące oprogramowania. Nawet jeśli będziesz umiał rozmawiać z klientami i rozwiązywać konflikty między zainteresowanymi stronami, wymagania mogą się zmieniać podczas tworzenia oprogramowania. Z tego względu jest bardzo mało prawdopodobne, że otrzymasz kompletne i prawidłowe wymagania dotyczące oprogramowania na początku projektu.
Jeśli popełnisz błędy na etapie analizy, większość z nich zostanie odkryta na etapie testowania, szczególnie gdy pokażesz klientowi swoje oprogramowanie podczas testów akceptacyjnych. W tym momencie model kaskady nie pozwalałby wrócić i naprawić napotkane problemy. Podobnie nie można zmienić wymagań w połowie procesu kaskadowego. Po zakończeniu fazy analizy projektu, proces kaskady „zamraża” wymagania. Po zakończeniu projektu otrzymasz oprogramowanie, które spełnia te wymagania, ale nie będą to poprawne wymagania.
Ostatecznie musisz powiedzieć klientowi, że dostał to, o co prosił, a nie to, czego potrzebował. Jeśli jest to programowanie na zamówienie, to klient będzie zirytowany; jeśli jest to oprogramowanie, które sprzedajesz (np. aplikacja mobilna), ludzie po prostu nie będą go kupować. Możesz również popełnić błąd na innych etapach projektu. Na przykład możesz sobie zdać sprawę, pisząc kod, z tego, że projekt, który wymyśliłeś, nie działa. Ale model kaskadowy mówi ci, że i tak musisz się z tym uporać i sprawić, aby jednak jakoś zadziałało.
Jeśli zatem model kaskadowy się nie sprawdza, to co możemy zrobić zamiast tego? Większość współczesnych procesów tworzenia oprogramowania opiera się na koncepcji iteracji. Przeprowadzamy trochę analizy, a następnie trochę projektowania, programowania i testów (taki cykl jest jedną iteracją). Daje nam to dość przybliżony prototyp tego, jak będzie wyglądał system. Możemy bawić się prototypem, pokazywać go klientom i sprawdzać, co działa, a co nie. Następnie powtarzamy wszystkie etapy w kolejnej iteracji. Ulepszamy nasze wymagania i projekt, programujemy i testujemy, aby nasz prototyp (kolejna iteracja) był lepszy. Z biegiem czasu prototyp rozwija się do postaci ostatecznego systemu, zbliżając się coraz bardziej do tego, co chcemy uzyskać. Metodologie oparte na tej idei są często określane jako zwinne (ang. agile) - mogą łatwo adaptować się do zmieniających się uwarunkowań.
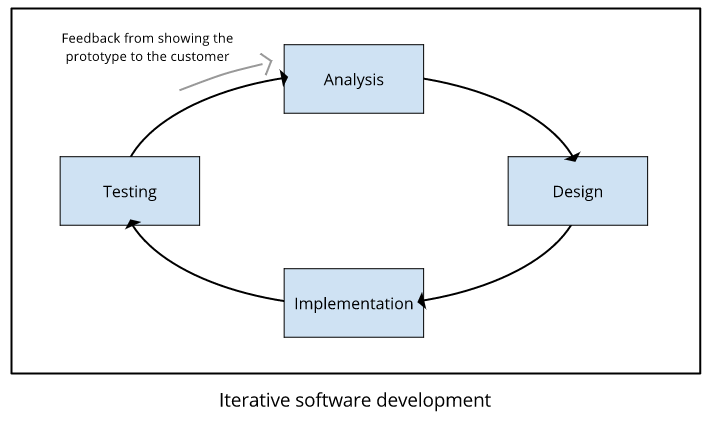
Zaletą takiego podejścia jest to, że jeśli popełnisz błąd, znajdziesz go po krótkim czasie (prawdopodobnie, gdy następnym razem przedstawisz prototyp klientowi) i będziesz miał możliwość go naprawić. To samo dotyczy sytuacji, gdy wymagania zmieniają się nagle; jesteś elastyczny i szybko reagujesz na zmiany. Dzięki temu podejściu otrzymasz znacznie więcej informacji od klienta, gdyż stopniowo będzie bardziej rozumiał swoje potrzeby.
Istnieje wiele iteracyjnych (używających iteracji) procesów tworzenia oprogramowania; przykładem popularnego procesu jest model spiralny. Chociaż procesy w szczegółach różnią się, wszystkie używają tej samej struktury iteracji i zwykle działają bardzo dobrze dla oprogramowania.
Poza pytaniem o to, co robimy w danym momencie realizacji projektu, kolejną interesującą kwestią jest to, ile czasu powinniśmy poświęcić na różne fazy projektu. Możesz myśleć, że największą częścią projektu informatycznego jest programowanie, ale w typowym projekcie programowanie zajmuje zwykle jedynie około 20% całkowitego czasu! 40% przeznacza się na analizy i projektowanie, a kolejne 40% na testowanie. To pokazuje, że inżynieria oprogramowania to znacznie więcej niż programowanie.
Po zakończeniu opracowywania programu i przekazaniu go klientowi, główna część projektu oprogramowania dobiegła końca. Jednak ważne jest, abyś nie przestawał nad nim pracować. Kolejna część projektu, która często trwa przez lata, nazywa się utrzymaniem. Podczas tej fazy naprawiasz błędy, zapewniasz obsługę klienta, a być może nawet dodajesz nowe funkcje, których potrzebują klienci.
-
Ciekawostka. Prawo Brooksa
Wyobraź sobie, że twój projekt jest spóźniony, a klient zaczyna się niecierpliwić. Twoim pierwszym odruchem może być poproszenie znajomych o pomoc, a tym samym zwiększenie liczby osób pracujących nad projektem. Prawo Brooksa sugeruje jednak, że to jest zły pomysł!
Prawo Brooksa stwierdza, że „dodanie siły roboczej do spóźniającego się projektu informatycznego opóźnia go jeszcze bardziej”. Na początku może się to wydawać sprzeczne z intuicją, która podpowiada, że więcej osób wykona więcej pracy. Jednak nakład pracy związany z wdrożeniem nowych osób w temat projektu (doprowadzenie do zrozumienia, co próbujemy zbudować, projektu struktury, istniejącego kodu itd.) oraz z zarządzaniem i koordynowaniem większego zespołu programistycznego sprawia, że w krótkiej perspektywie postęp staje się wolniejszy.
-
Projekt. Zabawa z kaskadą i zwinne procesy
Model kaskadowy jest prosty i powszechnie stosowany, ale nie sprawdza się w praktyce informatycznej. W tym ćwiczeniu dowiesz się dlaczego tak jest. Najpierw utworzysz projekt, który następnie przekażesz innej grupie. Muszą go dokładnie zaimplementować i nie mogą wprowadzać żadnych zmian, nawet jeśli coś nie działa!
Potrzebujesz talii kart i co najmniej 6 osób. Zacznij od podzielenia ich na grupy około 3 -- 4 osób. Musisz mieć co najmniej dwie grupy. Każda grupa powinna chwycić dwa krzesła i umieścić je w odległości około 30 cm. Zadanie polega na zbudowaniu mostu między dwoma krzesłami za pomocą kart z talii!
Zanim zaczniecie budować rzeczywisty most, musicie przemyśleć kwestię budowy mostu z kart. Przedyskutuj z członkami zespołu pomysł i zapisz jego krótki opis. Dołącz rysunek, aby wasz opis był zrozumiały dla innych.
Teraz wymieńcie się projektami z inną grupą. Użyj talii kart, aby spróbować zbudować most zgodnie z dokładną specyfikacją drugiej grupy. Nie możesz zmienić ich projektu w żaden sposób (postępuj zgodnie z modelem kaskadowym!). Może to być frustrujące (zwłaszcza jeśli wiesz, jak naprawić projekt), jeśli okaże się, że projekt się nie sprawdza!
Jeśli udało wam się zbudować most, twoja grupa oraz grupa odpowiedzialna za specyfikację zasługują na gratulacje! Jeśli budowa się nie powiodła, to możesz porozmawiać z drugą grupą i przekazać jej opinie na temat projektu. Powiedz im, jakie problemy miałeś, co zadziałało, a co się nie sprawdziło. Druga grupa powie Ci o problemach, które mieli z twoim projektem!
Udoskonal swój projekt, korzystając z wiedzy uzyskanej od drugiej grupy. Możesz eksperymentować z kartami i zmieniać projekt, gdy sprawdzisz, że coś nie działa. Jest to przykład podejścia zwinnego, które poznamy bliżej w dalszej części rozdziału. Wykonuj iterację (opracowywanie pomysłów), aż uzyskasz coś, co działa.
Które z tych podejść sprawdza się lepiej -- projektowanie wszystkiego na początku, czy działanie w stylu zwinnym?
-
Projekt. Język nawigacji
W tym ćwiczeniu opracujesz język do poruszania się po swojej szkole. Wyobraź sobie, że musisz opisać swojemu koledze, jak dostać się do konkretnej sali lekcyjnej. Ten język pomoże ci podać dokładny opis, który poprowadzi kolegę do celu.
Najpierw określ, do czego ma służyć język (znajdź wymagania). Czy twój język będzie przeznaczony dla całej szkoły czy tylko niewielkiej części? Jak dokładne będą opisy? Jak długie będą opisy? Jak łatwo będzie podążać za instrukcjami języka komuś, kto zna / nie zna twojego języka? Jak łatwo będzie można się go nauczyć? …
Teraz śmiało możesz zaprojektować język. Wymyśl różne polecenia (np. skręć w lewo, przejdź do przodu 10, …). Upewnij się, że wyposażyłeś język we wszystkie polecenia potrzebne do wyrażenia, jak dostać się z jednego miejsca w szkole do innego!
Na koniec przetestuj język, używając innego ucznia. Nie mów im, dokąd zmierzają, po prostu daj im instrukcje i zobacz, czy przestrzegają ich poprawnie. Wypróbuj różne przypadki, aż będziesz pewien, że twój język działa i że masz wszystkie potrzebne polecenia. Jeśli znajdziesz jakieś problemy, wróć, napraw je i spróbuj ponownie!
Zwróć uwagę, ile czasu zabiera ci każda z różnych faz projektu. Kiedy skończysz, porozmawiaj o tym, ile czasu poświęciłeś danemu etapowi i porównaj z danymi innych uczniów. Która faza była najtrudniejsza? Która trwała najdłużej? Czy uważasz, że powinieneś mieć więcej czasu na niektóre fazy? Jakie problemy napotkaliście? Co zrobiłbyś inaczej następnym razem?
-
Projekt. Budowanie z klocków (precyzyjna komunikacja)
Dobra komunikacja z innymi informatykami i klientami jest niezbędna dla programistów. W tym zadaniu możesz ćwiczyć precyzyjną komunikację!
Dobierz uczniów w pary, z jednym twórcą i jednym budowniczym. Każda osoba potrzebuje zestawu co najmniej 10 kolorowych klocków (np. klocków Lego). Upewnij się, że każda para ma taki sam zestaw bloków, inaczej to ćwiczenie nie zadziała!
Osoby w parze nie powinny widzieć się nawzajem, ale muszą być w stanie słyszeć się, aby się komunikować. Umieść przegrodę pomiędzy osobami w każdej parze lub każ odwrócić się w przeciwne strony. Twórca ma za zadanie zbudować coś z klocków. Im bardziej kreatywny będzie, tym bardziej interesujące będzie to zadanie!
Kiedy twórca zakończy budowę, przychodzi kolej budowniczego. Jego celem jest zbudowanie dokładnej repliki budowli twórcy (ale oczywiście bez znajomości wyglądu). Twórca powinien dokładnie opisać, co należy zrobić z klockami. Na przykład twórca może powiedzieć „Umieść mały czerwony klocek na dużym niebieskim klocku” lub „Ustaw dwa długie niebieskie klocki pionowo w odległości jednego klocka między nimi, a następnie umieść czerwony klocek na nich”. Twórca nie powinien opisywać budynku jako całości („Utwórz framugę”).
Kiedy budowniczy dochodzi do wniosku, że kopia jest gotowa, należy porównać obie konstrukcje. Jak precyzyjna była komunikacja? Które części były trudne do opisania dla twórcy lub niejasne dla budowniczego? Zmień role, aby uczestnicy mogli poznać obie strony!
Zwinne tworzenie oprogramowania stało się popularne w ciągu ostatnich 10 lat; dwa najbardziej znane procesy zwinne to XP i Scrum. Zwinne tworzenie oprogramowania jest niezwykle elastyczne i łatwo dostosowuje się do zmian. Większość innych procesów tworzenia oprogramowania stara się mieć pod dużą kontrolą zmiany podczas procesu; zwinne procesy akceptują i oczekują zmian. Poniższy komiks xkcd ilustruje część pozornego dylematu, z którym muszą się zmierzyć procesy zwinne. Dzięki metodologii zwinnej możemy szybko i poprawnie tworzyć oprogramowanie i dostosowywać je do zmian.

Procesy zwinne działają podobnie do procesów iteracyjnych, ponieważ wykonują wiele iteracji analizy, projektowania, implementacji i testowania. Jednak te powtórzenia są niezwykle krótkie, gdyż trwają zwykle tylko około 2 tygodni.
W wielu innych procesach ważnym elementem jest dokumentacja. Zawiera ona wymagania oraz opis projektu, tak abyśmy mogli się do nich odwoływać, gdy programujemy system. Zwinne procesy programowe zakładają, że rzeczy będą się zmieniać przez cały czas. Dlatego też bardzo mało planują i dokumentują. Wynika to z faktu, że dokumentowanie rzeczy, które i tak ulegną zmianie, jest raczej stratą czasu.
Zwinne procesy postulują wiele interesujących zasad, które odróżniają to podejście od standardowego tworzenia oprogramowania. Poniżej znajduje się ich przegląd. Jeśli chcesz dowiedzieć się więcej, zajrzyj do Agile Academy na Youtube, gdzie znajdziesz wiele filmów o ciekawych zwinnych praktykach!
Oto kilka ogólnych zasad stosowanych w programowaniu zwinnym:
Programowanie odbywa się w parach, jedna osoba pisze kod, podczas gdy druga przygląda się, szuka błędów i specjalnych przypadków, które mogły zostać pominięte. Chodzi po prostu o wyłapanie drobnych błędów, zanim staną się poważnymi błędami. W końcu co dwie pary oczu to nie jedna.
Można by pomyśleć, że programowanie w parze nie jest zbyt wydajne i że bardziej wydajne byłoby programowanie samodzielne; w ten sposób można przecież szybciej pisać kod, nieprawdaż? Celem programowanie w parach jest zmniejszenie liczby błędów. Testowanie, znajdowanie i naprawianie błędów jest trudne; staranie się nie tworzyć ich w pierwszej kolejności jest łatwiejsze. W rezultacie programowanie parami okazało się wydajniejsze od wszystkich programujących samodzielnie!
YAGNI oznacza „Nie będziesz tego potrzebował” (ang. „You ain’t gonna need it”) mówi programistom, aby dbali o prostotę oraz aby projektowali i implementowali tylko te rzeczy, które naprawdę są potrzebne. Można ulec pokusie, że skoro w przyszłości może się przydać funkcja x, to należy ją niezwłocznie zaimplementować. Pamiętaj, że wymagania ciągle się zmieniają, więc może się okazać, że jednak x nie jest potrzebne.

Nie będziesz tego potrzebował!
Programowanie zwinne bardzo poważnie traktuje testowanie. Zwykle polega ono na wielu zautomatyzowanych testach jednostkowych, które są uruchamiane co najmniej raz dziennie. W ten sposób, jeśli zostanie wprowadzona zmiana (co się często zdarza), możemy łatwo sprawdzić, czy ta zmiana spowodowała nieoczekiwany błąd.
Istnieje wiele różnych sposobów projektowania i programowania systemu informatycznego. YAGNI zaleca zacząć od najprostszej możliwej rzeczy. Wraz z rozwojem projektu może zajść potrzeba zmiany pierwotnego, prostego projektu. Zmianę tę nazywamy refaktoryzacją.
Refaktoryzacja oznacza zmianę projektu lub implementacji, bez zmiany zachowania programu. Po refaktoryzacji program będzie działał dokładnie tak samo, ale będzie w pewien sposób lepiej zorganizowany. Testy jednostkowe naprawdę przydadzą się w tej sytuacji, ponieważ można ich użyć do sprawdzenia, czy kod działa w ten sam sposób jak przed refaktoryzacją.
Refaktoryzacja działa w przypadku oprogramowania (w przeciwieństwie do budowy mostów), ponieważ programowanie jest elastyczne. Ta sama koncepcja nie zadziała w przypadku produktów inżynierii fizycznej. Wyobraź sobie, że budując most, zacząłeś od zrobienia najprostszej rzeczy (położyłeś deskę nad rzeką), a następnie zacząłeś refaktoryzować most, aby w końcu uzyskać solidny most...
W standardowym rozwoju oprogramowania najpierw piszemy kod, a następnie testujemy. Ma to sens: potrzebujemy kodu, zanim będziemy mogli go przetestować. Rozwój oparty na testach (ang. test-driven development -- TDD) zaleca, aby postępować dokładnie odwrotnie!
Zanim napiszesz fragment kodu, powinieneś napisać test kodu, który zamierzasz napisać. To zmusza do myślenia o tym, co dokładnie próbujesz osiągnąć i jakie są specjalne przypadki. Oczywiście jeśli spróbujesz uruchomić test, to się nie powiedzie (ponieważ funkcjonalność, którą testuje, jeszcze nie istnieje). Aby testowanie miało sens, należy po prostu napisać kod poprawnie implementujący funkcjonalność.
Twórcy oprogramowania nie powinni pracować dłużej niż 40 godzin tygodniowo. Jeśli pracują w trybie nadgodzin w jednym tygodniu, to nie powinni tego robić w następnym. Dzięki temu możemy utrzymać programistów w stanie zadowolenia, mogą być produktywni, kreatywni i energiczni oraz mamy gwarancję, że nie są przepracowani.
Przedstawiciel klienta powinien być członkiem zespołu rozwijającego oprogramowanie (w najlepszym przypadku powinien spędzać cały czas z zespołem), powinien być pod ręką, aby móc odpowiadać na pytania i wyrażać opinię w każdej chwili. Jest to istotne, gdyż pozwala szybko zmieniać wymagania lub kierunek projektu. Jeśli musisz czekać 2 tygodnie, zanim uzyskasz informację zwrotną od klienta, nie będziesz w stanie szybko dostosować się do zmian!
Chociaż posiadanie przedstawiciela klienta w zespole programistów jest świetnym pomysłem, w praktyce jest to dość trudne do osiągnięcia. Większość klientów po prostu chce przekazać wymaganie, zapłacić, a następnie odebrać oprogramowanie w ustalonym terminie. Rzadko zdarza się znaleźć klienta, który jest chętny i ma czas na większe zaangażowanie w projekt. Czasami firmy zatrudniają eksperta, który staje się częścią zespołu; na przykład firma zajmująca się oprogramowaniem dla opieki zdrowotnej może mieć w zespole lekarza lub jeśli pracuje nad oprogramowaniem edukacyjnym, może zatrudnić nauczyciela. Wydaje się to kosztownym rozwiązanie, ale ponieważ nieudane oprogramowanie może kosztować miliony, wypłacanie wynagrodzenia ekspertowi stanowi stosunkowo niewielką część całkowitych kosztów, a znacznie zwiększa prawdopodobieństwo sukcesu.
-
Ciekawostka. Christopher Alexander
Do tej pory porównywaliśmy rozwój oprogramowania głównie do inżynierii i budowania mostów, ale mogłeś zauważyć, że jest również bardzo podobny do architektury. W rzeczywistości rozwój oprogramowania (w szczególności zwinne tworzenie oprogramowania) zapożyczyło wiele koncepcji z architektury. Architekt Christopher Alexander zasugerował zaangażowanie klientów w proces projektowania. Brzmi znajomo? Kilka innych sugestii od Christophera Alexandra zostało również przejętych przez zwolenników zwinnego programowania. W rezultacie jego myślenie o architekturze ukształtowało nasz sposób myślenia o rozwoju oprogramowania. Dzieje się tak pomimo faktu, że Christopher Alexander nie wiedział nic o programowaniu. Okazało, że był bardzo zaskoczony, gdy dowiedział się, że jest dobrze znany wśród programistów!
„Odwaga” może wydawać się dziwnym pojęciem w kontekście rozwoju oprogramowania. W procesach zwinnych rzeczy zmieniają się cały czas i dlatego programiści muszą mieć odwagę, aby wprowadzić zmiany w kodzie, naprawić problemy, poprawić projekt, wyrzucić kod, który nie działa, i tak dalej. To może nie wydawać się wielkim wyzwaniem, ale zmiana kodu może być dość przerażająca, szczególnie jeśli kod jest rozbudowany lub został napisany przez inną osobę. Testy jednostkowe naprawdę pomagają, dodając odwagi: będziesz mieć większą pewność, że zmieniając kod, nie popsujesz go.
-
Projekt. Procesy tworzenia oprogramowania
Realizacja tego projektu umożliwi wgląd w prawdziwy proces inżynierii oprogramowania, ale musisz znaleźć inżyniera oprogramowania, który udzieli odpowiedzi na pytania dotyczące jego pracy. Najlepiej jeśli osoba ta pracuje w średniej lub dużej firmie, w której jest częścią zespołu inżynierii oprogramowania (tzn. nie jest samotnym programistą).
Zadanie polega na przeprowadzeniu wywiadu z osobą doświadczoną w rozwijaniu oprogramowania. Pamiętaj, że takie osoby mogą niechętnie rozmawiać o projektach firmy i że należy zapewnić im poufność (wyniki zadania powinny być dostępne tylko uczestnikom oraz osobom zaangażowanym w jego nadzorowanie, powinieneś o tym poinformować wyraźnie na samym początku, aby zapobiec niepożądanym publikacjom).
Musisz dobrze przygotować się do tej rozmowy. Dowiedz się o oprogramowaniu, które firma zaproszonego programisty wytwarza. Poczytaj o inżynierii oprogramowania (w tym rozdziale), aby poznać główną terminologię i techniki.
Przygotuj listę pytań dla gościa. Powinny one dotyczyć tego, jakiego rodzaju procesy rozwoju oprogramowania są używane przez jego zespół, nad jakimi aspektami pracuje rozmówca oraz jakie są dobre i złe strony stosowanego procesu. Przy okazji proś dyskutanta o przykłady.
Powinieneś sporządzać obszerne notatki podczas wywiadu (a nawet nagrywać, jeśli dana osoba nie ma nic przeciwko).
Następnie powinieneś napisać, czego się nauczyłeś, opisać proces, omówić stosowane techniki, zilustrować je przykładami i ocenić, jak dobrze działa dany proces.
W tym rozdziale staraliśmy się przedstawić wyzwania związane z tworzeniem oprogramowania i technikami używanymi przez programistów do ich przezwyciężenia. Tak naprawdę tylko dotknęliśmy zagadnień analizy oprogramowania, projektowania, testowania i procesów oprogramowania; istnieją całe książki poświęcone tym tematom!
Zrozumienie znaczenia niektórych problemów i technik, które tutaj opisaliśmy, może być trudne. Szczególnie jeśli sam nigdy nie pracowałeś nad większym projektem informatycznym. Niektóre mogą wydawać się dla ciebie zadziwiająco oczywiste, inne mogą wydawać się nieistotne. Kiedy będziesz pracował nad swoim pierwszym dużym projektem, wróć do tego rozdziału i, miejmy nadzieję, rozpoznasz niektóre przedstawione tu problemy!
Wszystie materiały w języku angielskim.
- Wikipedia -- inżynieria oprogramowania;
- CS4FN -- inżynieria oprogramowania;
- Nauka ICT -- o cyklu życia systemów;
- Wikipedia -- kryzys oprogramowania;
- IEEE -- Dlaczego oprogramowanie zawodzi?;
- Wikipedia -- projektowanie oprogramowania;
- Wikipedia -- abstrakcja;
- Wikipedia -- testowanie oprogramowania;
- Wikipedia -- procesy rozwoju oprogramowania;
- Wikipedia -- model kaskadowy;
- Wikipedia -- model przyrostowy;
- Wikipedia -- programowanie zwinne;
- Wikipedia -- rozwój oprogramowania oparty na testach.